Web Research: Browsing Video Content
Interactive Media-rich Web Content - Using Video
One of the major problems experienced by Web users is the amount of time needed to download data. As the speed and power of desktop computer has increased it has become possible for almost anyone with access to a PC to produce interactive web content using images, audio, and particularly video. Therefore, even though the available bandwidth of the Internet is increasing, the bandwidth requirements of the media available through it, and the number of users trying to access that information are also increasing. Although estimates vary wildly, the evidence is of massive, rapid, growth: the number of Web pages in September 1997 was 200M; the average time spent online in 1996 was 6.9 hours a week, and in 1997 9.8 hours; in 1997 there were an estimated 26M hosts, with 300,000 pages added to the net every week; information on the Internet doubles every year with 100 million people using the Internet, over 1.5 domain names, and a doubling of internet traffic every 100 days. These factors combine to ensure that the effective bandwidth available per person is still low enough to make the downloading of some Web content take a long time.
The browsing model on which the web is based exacerbates this problem. As hyperlinks are references to new information, users do not know exactly what that information is until it has been fully downloaded. If the data takes many minutes, or even hours, to download, the browsing model begins to break down, and finding information can become a time consuming, expensive, and frustrating task.
In the case of video the problems are more pronounced. Although video is a powerful communicative tool, especially for interactive web-based content, the large volume of raw data required for digital video sequences makes accessing video sequences from remote servers a time consuming and expensive task, with even small sequences taking many minutes or even hours to download. It would therefore be valuable to ensure that the video data being retrieved by the user is exactly that which meets their requirements.
Video as Data
Video has a number of properties that present a particular challenge to efficient storage and retrieval. These properties are (i) the high volume of data needed to encode even short sequences of video, (ii) the temporal component of video, and (iii) the opacity of video to computers.
In the case of (i), data volume, the drawback of video as a medium is the sheer volume of raw data required to communicate and store it. A single frame of broadcast television in the United States, for example, consists of 525 lines of colour and luminance information: by sampling at the same horizontal and vertical frequencies (i.e. using square shaped pixels), and representing each pixel by three 8-bit colour values (one for each of the red, green, and blue colour channels), over a megabyte of memory is required to store a single television frame. Furthermore, because US television pictures are refreshed thirty times per second, it requires 33 megabytes of memory to store a single second of television content.
The second property that ensures that video is difficult to store and retrieve in a convenient and efficient manner is its spatio-temporality. Still images and text are spatial media: the information that they carry is spread out over an area in space, be it a sheet of paper, an artist’s canvas, or a computer screen, and it does not change over time. Images can be almost fully understood at a glance and a page of text can be read very quickly to identify which sections are relevant. Speech and other audio information by contrast are temporal media: it is meaningless to ask what sound can be heard at a given instant in time, because sound does not exist independently of time. The temporal nature of speech and other audio information presents a problem when trying to browse or navigate through such media, because neither their general structure, nor an overview of their contents can be quickly assessed.
Video, like images and rendered text is displayed over a spatially but like audio, video information has a temporal component and so is a spatio-temporal medium with all the restrictions of temporal media rather than the advantages of spatial media. Although an individual frame of a video sequence may be treated as a still image much of the important information in a video sequence is contained within its temporal component, and is not shown by a single still image. Like audio, if the user wishes to understand a ten-minute sequence of video they must take ten minutes to watch the whole sequence.
In the case of (iii) textual information stored on computers is relatively easy to catalogue, search, and access, but images are not generally constructed from an easily identified and finite set of primitives and because of this their content and structure cannot easily be analyzed.
Rosetta - a Video Storyboarding System
We have developed a system called Rosetta which creates from video content a series of video stills representing a sequence of video footage. This representation - a storyboard - is routinely used in the production of all types of film, video and animation and consist of a series of sketches showing each shot in each scene as it will be filmed, and possibly some indication of the action taking place. A storyboard allows the writers and directors to plan the action to be shot and from what camera angle, and in essence provides a summary of the entire film.
Normally, the storyboard is not available to a viewer as it is discarded after the movie is completed. If however, the storyboard for a piece of video, or a close approximation to it, could be generated from the video itself, then the viewer could be provided with an easy means of browsing and indexing an entire video sequence.
Figure 1 shows part of the original storyboard for the Oscar-winning animation The Wrong Trousers (Aardman Animation, UK).

Figure 1: Part of the original storyboard for the Oscar-winning animation The Wrong Trousers
The Rosetta system, which is intended to produce storyboards in real time or faster then real time, has been tested by reverse-engineering storyboards from finished video sequences. The system identifies three properties of each shot in the sequence: (1) the start point (first frame) of the shot, (2) the end point (last frame) of the shot, and (3) the picture that represents the shot as a whole. The first two of these properties may be found by a process of transition detection and the third by representative frame choice. Transitions are the links between successive shots in sequences. The most frequently used type of transition is the cut, but effects such as fades, dissolves, and wipes are also used. Transitions are detected by comparing the amount and constancy of change between individual frames.
Having identified the start and finish of each shot, an image must be produced that conveys the same meaning as the entire shot. In Rosetta, a single frame from the shot is chosen as being representative. The algorithm compares each frame in the shot to an ‘average frame’ generated by simply finding the mean colour of the corresponding pixels in each frame of the shot. Originally, the algorithm was designed to choose the frame that differs least from the average frame (the typical frame). Better results can be obtained by choosing the frame that differs most from the average frame (the atypical frame).
Figure 2 shows part of the Rosetta-generated storyboard from the video of The Wrong Trousers. Comparison with the original storyboard fragment in Figure 1 reveals that Rosetta delivers a storyboard very close to the original. Aspects of Rosetta are described in detail in references [1-9].

Figure 2: Part of the Rosetta-generated storyboard from the video of The Wrong Trousers
Rosetta on the Web
The value of Rosetta is to produce storyboard representations of video sequences accessible through the World Wide Web. Because the data size of a storyboard representation is negligible when compared to that of the video sequence itself, each frame of the storyboard may be stored together with information about the start and finish frame numbers of the shot which it represents with negligible additional storage requirements. By presenting a storyboard representation of the video sequence to the user as a preview of the video sequence itself, the user will be able to quickly assess which parts of the video sequence are required, and download only those parts of the sequence, and in a form which is most appropriate to their needs.
It is relatively simple for a server to automatically generate an HTML document displaying any part of the storyboard in a number of different possible formats including arbitrarily complex user interaction capabilities made possible using applets. Using forms, control elements such as buttons and selection boxes can be made to appear on the web page. In the example in Figure 3, three check boxes are included under each frame of the storyboard. The first check box is accompanied by a magnifying glass icon, and may be selected to download a larger version of the image; the second, next to a loudspeaker icon, may be selected to download the audio track from the appropriate section of the video sequence; while the third, shown with a film projector icon, may be used to download the digital video itself.
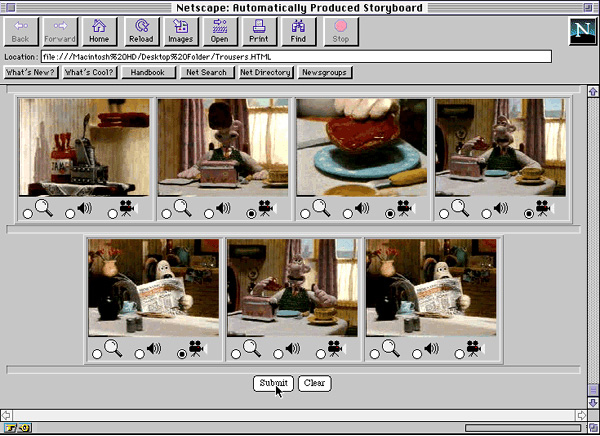
Figure 3: User Interface
Once a browser has downloaded and displayed the HTML page showing the storyboard, the users may look through the sequence of still images and decide if they require any additional representations of each shot to be downloaded. A larger version of the representative frame, the audio track associated with the shot, or the full-motion digital video clip itself may be requested by selecting the appropriate check box under each frame.
When a video server receives a request for an alternative media, it is dealt with by a CGI script which parses an ASCII string description of the selections supplied by the browser. Having established which additional media are required for which shots, the script can locate the required data, encode it in an appropriate format, and send the requested media back to browser. The encoding in which the media is being sent (MPEG, GIF, etc) is identified by the MIME type included in the header information. When the client receives the additional media requested by the user, the browser will examine the MIME type information associated with the data. Standard browsers are generally only capable of displaying a very limited set of media types in few encodings, (hypertext, and gif and JPEG encoded still images) but this basic functionality may often be expanded by the addition of plug-ins. If the browser includes a plug-in capable of decoding and playing the MIME type of the additional media, then it will be displayed by the browser itself. Alternatively, the browser may be able to associate the MIME type with an external viewer, and send the additional media type to this application. Figure 4 shows this process.
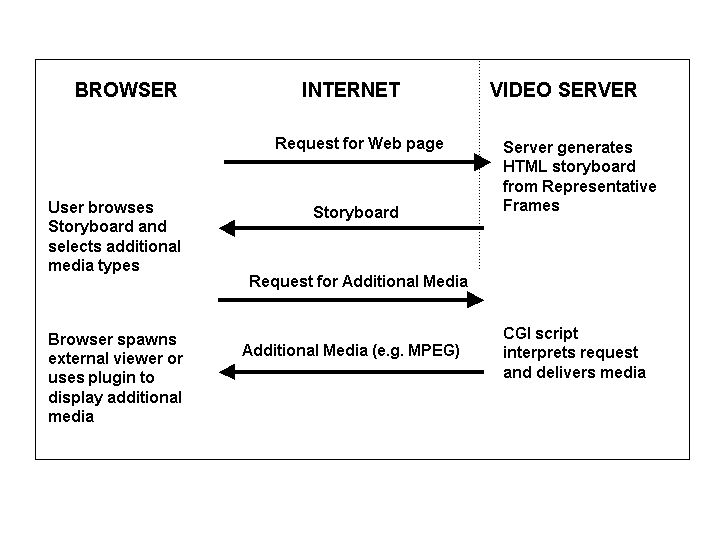
Figure 4: Model for dialogue between browser and server
Developing Rosetta
There are several developments of Rosetta as it stands which would be useful. One is to generate storyboards directly from compressed data. The algorithms used in Rosetta for cut detection only require the average colour within each of a number of blocks which each frame is divided into. Because compression schemes commonly used on image and video themselves divide each frame into a number of smaller blocks applying a discrete cosine transform (DCT) to each one, coupled with the fact that the first coefficient of the resulting DCT is equivalent to the average colour over that block, it seems likely that the required information can be extracted from a compressed data stream with only partial decompression.
A second development is to attempt to make use of available a priori information. In the case of the Representative Frame Choice algorithm this would mean weighting the decision of which frame is selected in favor of those which are known a priori to be most likely the best choices. For example, it is assumed that the best frames typically come from near the middle of the shot, with less suitable frames being found toward the beginning and end. The frame choice can then be weighted to take this a priori knowledge into account.
References
- Macer, P. and Thomas, P. (1996a)
From Video Sequence to Comic Strip: Summarising Video for Faster WWW Access. Proceedings of 3D Graphics and Multimedia on the Internet, WWW and Networks, British Computer Society Computer Graphics & Displays Group, 16-18 April 1996. - Macer, P. and Thomas, P. (1996b)
Video Storyboards: Summarising Video Sequences for Indexing and Searching of Video Databases. IEE E4 Colloquium Digest on Intelligent Image Databases, Savoy Place Wednesday, 22 May 1996. - Macer, P. and Thomas, P. (1999a)
Browsing Video Content. Proceedings of BCS HCI Group Conference, The Active Web, January 1999, Staffordshire University, UK. - Macer, P. and Thomas, P. (1999b, in preparation)
Evaluation of the Rosetta Video Summarising System. - Macer, P. and Thomas, P. (1999c, in preparation)
Video Browsing using Storyboards. - Macer, P. and Thomas, P. (1999d, in preparation)
An empirical comparison of algorithms for representative frame selection in video summarising. - Macer, P. and Thomas, P. (1999e, in preparation)
Accessing video over the web. - Macer, P. and Thomas, P. (1999f, in preparation)
Transparent Access to Video Over the Web: a review of current approaches. Proceedings of BCS Conference on Mew Media Technologies for Human-centred Computing, National Museum of Photography, Film & Television, Bradford, UK 13-15 April 1999. - Macer, P., Thomas, P. Chalabi, N. and Meech, J. (1996)
Finding the Cut of the Wrong Trousers: Fast Video Search Using Automatic Storyboard Generation. Proceedings of CHI’96 Human Factors in Computing Conference, Vancouver, April 1996.
Author Details
Peter J. Macer
Hewlett Packard Research Laboratories, Filton Road, Stoke Gifford, Bristol BS12 6QZ
Email: pejm@hplb.hpl.hp.com
Peter Macer is a Senior Member of Technical staff at Hewlett Packard Research Laboratories, Bristol and holds a PhD from UWE, Bristol.
 Peter J. Thomas
Peter J. Thomas
Centre for Personal Information Management
Faculty for Computer Studies and Mathematics
University of the West of England
Bristol BS16 1QY
Email: Peter.Thomas@uwe.ac.uk
Peter Thomas is Professor of Information Management and Director of the Centre for Personal Information Management at UWE, Bristol.