The Filling in the PIE: HeadLine's Resource Data Model
This article explains the concepts of representation and use of metadata describing library information resource collections in the Resource Data Model (RDM) that has been developed by the HeadLine project [http://www.headline.ac.uk/]. It is based on documentation originally intended for library staff who may become involved in maintenance of metadata in the RDM, as the deliverables of the project are handed-over into mainstream use. An earlier published article [Graham] was based on the first (un-released) version of the HeadLine RDM, to which this is intended to be an update.
The RDM is designed as a relational database, and implemented using only standard and portable Standard Query Language (SQL) complying with the ANSI/ISO SQL-92 Standard SQL. It was developed using the PostgreSQL database [http://postgresql.readysetnet.com/] in a Linux environment, but does not use any functionality that is proprietary to PostgreSQL, and can therefore be implemented on most available relational database management system products. The RDM package also includes a library of access routines written in object Perl (version 5) [http://www.perl.com/], via which user interface applications (for either end-user access, or for metadata maintenance by library staff) can be implemented to access the logical structure of resource records without detailed knowledge of SQL, or of the internal structure of the RDM database. However, this paper also contains details of that internal structure to facilitate the implementation of simple interfaces for specific metadata maintenance tasks using non-Perl-compatible tools (such as the creation of task-specific relational database views, or direct ODBC connection to the RDM database from Microsoft Windows-based tools such as Excel and Access).
Why the RDM was developed
The HeadLine project started with the assumption that ROADS http://www.roads.lut.ac.uk/ was established as a de-facto standard that would be adopted by projects within the eLib Programme. In the course of our design and development phases it became clear that if we were to accurately model resource metadata in the level of detail we needed, then we would have to adopt a more structured model, and the database technologies to support it. This was a controversial decision by the project at the time, although since then others, including the developers of ROADS (which is used as a platform for SOSIG [http://www.sosig.ac.uk/] and other JISC-supported resource gateway services) have since come to very similar conclusions [Hamilton].
The RDM was originally designed to meet the requirements of the HeadLine Personal Information Environment (PIE) [McLeish] [Gambles] for richly functional collection-level metadata about the whole range of information resources available in a ‘hybrid library’ [Rusbridge]. The PIE also uses a relational database (to describe users and to manage sessions), but this was deliberately designed (at some short-term performance cost) to be separate from, and not to be closely coupled with the RDM database.
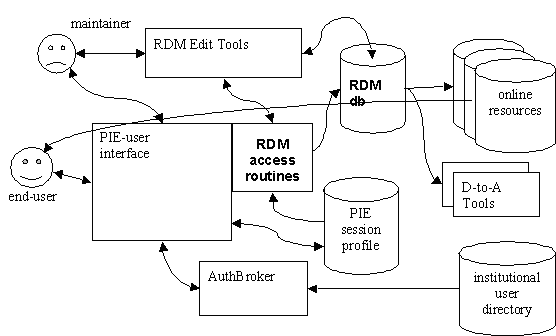
Figure 1: Relationship of the RDM to the PIE and other HeadLine components
The RDM as a shared and re-usable library tool
The main reason for this design decision was our recognition of what is likely to be the most critical factor in the successful adoption of the PIE (and probably most other personalised, user-centric library services like the PIE): identifying a sustainable model for maintaining the rich and detailed resource metadata without which it cannot function.
The PIE, and services like it [Morgan] [ExLibris], are most likely to be each implemented, configured, maintained and operated by a single library or university. To end-users for whom they are the main channels of access to a library service, they will effectively become the identity, ‘branding’ or ‘added value’ represented by that library. A single PIE is unlikely to be operated across several libraries, unless they are also very closely related organisationally (such as with several faculty libraries of one university, or all the branches of one public library service).
There are two potential areas in which costs might reasonably be shared, without compromising this principle:
- Facilities management models in which the capital costs and technical support burden of server and network hardware and software to support many PIEs might be contracted out or undertaken on a consortial basis.
- Some metadata about library resource collections (such as nationally or globally available online resources) clearly can (and ideally should) be maintained just once (probably by the resource provider or publisher), and the costs and benefits shared by all libraries that subscribe to the resource.
However, a library (or a library service director with any sense of self-preservation) is unlikely to decide to externalise or otherwise completely abdicate its’ role of maintaining metadata about the resources it provides (and guides the use of) for its’ users - without risking the loss of its’ entire reason for existence except as a building in which to store a lot of books.
Maintenance of this metadata is a seriously non-trivial task, needing serious commitment of library staff with appropriate ‘traditional’ cataloguing skills, a good understanding of the more technical metadata elements needed for non-print resources (such as the parameters needed for configuration of a Z39.50 [http://www.niso.org/z3950.html] search target), and also an appreciation of the reasons why metadata needs to be more complex and structured than the simple ‘flat’ records of a bibliographic catalogue. (This paper is intended to help develop that appreciation).
Our three reasons, then, for developing the RDM in a way that enabled it to stand alone from the PIE were:
- Pragmatic: within a limited period of the project, we could independently progress development of the PIE software and the RDM; in fact, the first released version of the PIE did not use the RDM (the development of which had been delayed by other factors), but some much-simplified temporary database tables to describe resources.
- Shareability: with only project staff to maintain the metadata, we could initially compile a single shared RDM database, for use by all the three versions of the PIE (customised for users at each of the three institutions where test users were participating in the project).
- Re-usability: once we had proved the concept of the RDM in use with the PIE, we could start to include the contents of other resource lists and databases, changing the applications that used them to access the same data from within the RDM instead, and diverting the (considerable) maintenance effort they required from library staff, to maintenance of the same data, as far as possible through (apparently) the same interfaces as before, in the RDM.
Existing services that the RDM can support
At LSE these existing but disparate lists of resource collections for library users were (or still are) each serving to facilitate end-user access to supposedly ‘different’ types of resource, such as e-journal titles, statistical datasets, networked CDs, and external web sites of various types. Some were implemented by hand-crafted static HTML pages, and others by small databases implemented for each purpose using Microsoft Access and similar tools. A previous (and highly successful) attempt to implement a single unified interface to many resources was EASI (‘End-user Access to Subject Information’ [TimG?]) which used an Access database and Access forms to store and maintain metadata, with some fairly simple scripts run as batch processes (whenever changes were made) to regenerate a set of static linked HTML pages, presenting end-users with lists of resources by subject or by title in alphabetic order.
During the design phases of HeadLine the functionalities of EASI and other end-user metadata services at all three participating libraries were analysed and used to define some of the functional requirements of the PIE and the RDM. It would therefore be surprising if the RDM as designed could not accommodate all the data in all of these separate services, and support all their previous functionality.
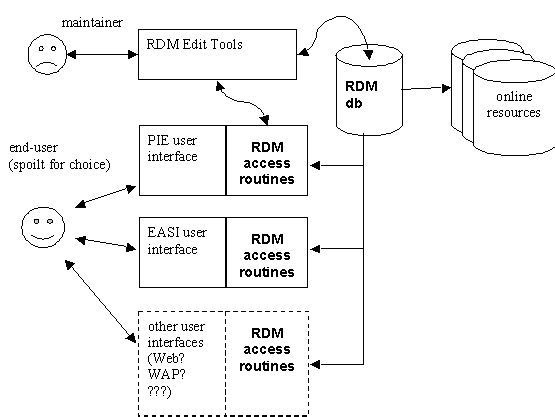
Figure 2: Possible relationships of the RDM to alternative end-user service interfaces
However, the HeadLine project and this design process also gave us an opportunity to take a more considered overview of the commonalities and differences between these services, and think of new ways to structure and maintain this information.
A wider model of the resource metadata architecture in a truly hybrid library would show a single repository, accessed by end-users through a number of channels or views, and possibly also maintained by library staff through several different interfaces.
Maintenance Interfaces to the RDM
We intend to provide a Web-based editing interface to the RDM for library staff users responsible for maintaining metadata about resource collections to which the library has access. This will be usable in a way that integrates with the existing Web-based page customisation facilities of the PIE, but should also be usable standalone, without a PIE. It will be important for library staff to understand the differences between their roles in editing data in the RDM (which may be used for many purposes), and editing customised pages in the PIE (which are each just one view of a set of resources described in the RDM). A PIE page maintained by a librarian may show, for example, all of those resources relevant to a particular academic department of the university. In this context it is also important to remember that relevance of a resource to a department of a particular university called (for example) “Economics” (and therefore inclusion of a pointer to that resource in a PIE page for the Economics Department), may not coincide with the term “Economics” as an appropriate subject or keyword (to be included in the RDM description of the resource).
The main problem we have faced in designing a maintenance interface for the RDM is that its’ structure is (necessarily) complex, but most maintainers don’t need to deal with most of that complexity. Our solution has been to delay implementing a fully functional RDM editor, and instead identify the different editing functions needed by different maintainers, prototyping temporary ‘limited view’ interfaces for each of these using ODBC [Microsoft] connections direct to the RDM database, and Microsoft Access table-views and forms. The simplest possible editing interface has consisted of only the default table-view of each of the RDM database tables (as ‘linked tables’ in Microsoft Access), plus a set of instructions [Noble] for editing; but we acknowledge that this is far from as “user friendly” as we would like!
This approach has the advantage that library staff who are not primarily IT specialists can relatively easily learn to build and modify their own editing forms, evolving the interfaces they want to show the information they want to see and edit, and none of the information that isn’t relevant to their task. There are some risks to the data in the RDM, because it is quite easy to damage the relational integrity of the database when accessing it this way. However, editing is relatively infrequent, so the risk can be protected against by reasonable backup procedures.
Because of the risks to the database, and the fact that direct access side-steps our own access routines (see below) and so avoids the RDM-specific data quality checks such as automatic attribution and time-stamping of record creation and updates, we don’t see this as a sound long-term method of implementing metadata maintenance. However, we will be able to use the forms and views developed as well-tried models for the rapid implementation of a Web-based maintenance interface in due course.
Encapsulation of the RDM by access routines
Where minor extra requirements for additions to the RDM emerged later (or are still to emerge), retro-fitting them to the RDM database should have no knock-on effects (and requirements for further changes) on the PIE (or on other applications using the RDM) because these don’t access the database directly but only via the library of access routines which encapsulates and effectively hides the internal structure of the database. Only any affected access routines need be changed, for even quite radical internal changes to the database. The combination of the RDM relational database and the access routines library effectively provides an object database view of the RDM.
Our intention in the future is to extend the library of access routines, to include facilities such as presentation of the RDM database as a Z39.50 target, or implementation of other interoperability protocols.
Wherever possible, access routines should be used to select from and update the RDM database, rather than direct SQL calls. If an appropriate access routine is not available, it is preferable to add a new one to the library if possible.
Beware of confusing access routines (as described above) with the access methods to the metadata or full-content of the resources described in the RDM.
The RDM Database structure
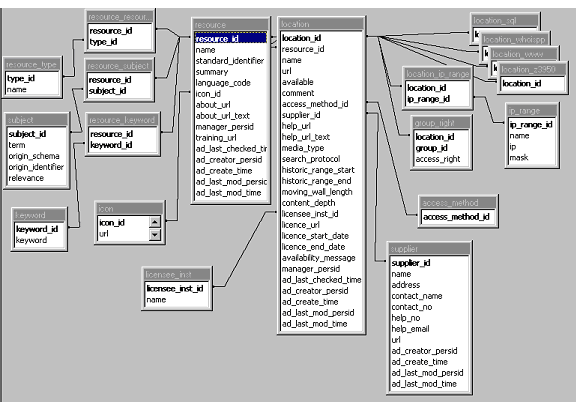
Figure 3: Tables, columns and relations within the RDM database (note: not all columns are shown here)
Records (database rows) in each main table of the RDM database are uniquely identified by an arbitrary numeric key named xxx_id (where “xxx” is the table name). Two such columns, identifying the two main tables they join, uniquely index tables implementing many-to-many joins. (The table group_right is an exception to this rule, being uniquely indexed by a pair of identifiers, but is not strictly a many-to-many join-table).
Resources, Locations and Suppliers
The Resource table could be seen as the core of the RDM. Each record describes a single identifiable collection-level [RSLP] resource or information product. A Resource may be uniquely identifiable by some externally-defined standard, such as ISBN or ISSN (standard_identifier); it should be based on a single main human language, defined by the language code used in Z39.50 http://www.oasis_open.org/cover/nisoLang3_1994.html.
A name and a short description (summary - normally one paragraph) can be included, and a URL (icon_id -> icon.url) referencing a graphic icon to represent the resource, all of which are intended to be displayed to end-users in brief listings of resources. A URL (about_url) can be used to reference longer explanatory information about the content of the resource, together with a textual label (about_url_text) for displayed links to this URL. Another URL (training_url) can reference details of local end-user training about use of the resource content (this is normally displayed by applications using a standard icon for training, so has no related label text). A contact person can be identified (by email address, normally of an appropriate RDM maintainer) to be responsible for the resource by manager_persid; applications may display this email address as “for further information, contact: “, or similarly.
Generally, a Resource record describes a collection of content, independent of the medium in which it is held or the arrangement for access to the content that may be made by any particular library. There may be some potential for sharing standard Resource records (like standard bibliographic cataloguing records) between libraries, although libraries may also want to exercise local control over the way in which a Resource is commonly named or described; and of course the displayable textual metadata will normally use just one natural language.
The Location table of the RDM is in fact where most maintenance activity will need to be focussed. Each Location record describes in detail, for a specific Resource, a holding of (or arrangement for access to) all or part of the content collection identified by the Resource, that is accessible to all or some users of a particular library. A single Resource may have one or more Locations.
Location fields that are normally intended for display to end-users are: url and comment - to reference the access address of the content, and to label that reference in listings; help_url and help_url_text - to reference (and label the reference of) explanatory information about the Location; availability_message to inform about circumstances under which the Location is (un-)available; manager_persid to identify the responsible maintainer. Other Location fields are not normally displayed to end-users, but are for the use of applications or maintenance administration. These include: name (used to identify a Location, such as a service, online server, or physical collection site, which may be common to several Resources); available (valued ‘Y’ or ‘N’ to indicate to applications whether a Location is currently available); supplier_id (linking to the Supplier table); access_method_id (linking to the Access_method table); licensee_inst_id (identifying the library holding the license for end-user access to this Location, where a RDM database is shared by more than one library); license_start_date, license_end_date and licence_url (the currency and reference to details of the license for access to this Location); media_type, search_protocol and content_depth (enumerated values for the media, search protocol and depth such as ‘full-text’, ‘abstract’, etc); historic_range_start, historic_range_end and moving_wall_length (for date-range information on Locations such as periodicals).
In some ways there are conceptual parallels between the Resource and its’ available Location(s) in the RDM, and the bibliographic record and its’ corresponding holding(s) records (one for each copy of the same book) in a traditionally structured library management system. The HeadLine project team suffered a crisis of terminology to arrive at the name “Location”, discarding first “Holding” (because many non-print resources are not “held” locally, but are physically stored by the supplier who grants access to users of a particular library), and then “Resource-Instance” (because it was confused with the relational database terminology for “an instance of a Resource” – meaning one row or record in the Resource database table).
Information in the Supplier table is purely for administration of contacts with resource vendors or other external suppliers, and is not normally visible to end-users. One or more Locations may be linked to a Supplier.
Subjects, Keywords, Resource-types and ‘use metadata’
A Resource can be described or classified by one or more records in each of the Resource-type, Subject, and Keyword tables, and can be depicted by a (single) graphical Icon. By implication, all such classifications of a Resource apply to all Locations of any subsets of the content of that Resource; it is important to remember that they describe the intellectual content of the Resource, not the technical or other details of any particular holding or access licence for all or some part of that content. Any particular Resource-type, Keyword, Subject (or Icon) may naturally be used for more than one Resource, and applications will commonly wish to present Resource metadata organised into lists by these classifications (“show resources in alphabetic order of subject”, “show only resources of the type ‘journal’”, etc).
A Resource-type classifies resources by function, rather than medium (so, a journal is always a journal, whether it’s on paper, CD, Web or all three), and values should be selected from the existing list where possible (although we have not been able to identify any authoritative set of definitions for these), or new values created (up to 30 characters long) with care to avoid ambiguity or duplication.
A Keyword is any term (up to 30 characters long) selected or created by the RDM maintainer to describe a Resource.
A Subject describes Resources in the same way as a Keyword, but must be chosen from an identifiable authoritative origin_schema - a controlled list or thesaurus of terms, and its’ normative origin_identifier (in that schema) should be included in the record.
Other metadata to facilitate the use of resources by end-users (resource.about_url, resource.training_url, location.help_url) is held directly in the Resource and Location tables, and has been described above.
Access Authorisation Control
The RDM implements control of access by end-users to resource Locations with two possible methods: ‘group-rights’ and ‘IP address discrimination’.
IP-address
This method is accepted as a ‘necessary evil’, and implemented in the RDM, because many supplier licences for content access are still restricted to on-campus users, or even specific identified workstations in a physical library building, despite the recognised demand for ‘anytime, anywhere’ access.
The IP_range table can be used to define named (for example, “library-building”) ranges of workstations by address (ip) and mask. Locations can then be linked, many-to-many, with these ranges.
Group-rights
The ‘group-rights’ method is favoured where available (and permitted by the license terms applicable to a Location), and is better for facilitating managed location-independent access by identified authorised users. It allows a library that holds metadata about a known community of users, such as staff and students of a university (this data is not included in the RDM, but is expected to be available from other management information systems) to assign groups to individual users (or, to groups of users), and then (within the RDM) assign various rights to any combination of user groups, in respect of access to any resource Location. This model for access management has been developed and described by the HeadLine project [Paschoud], and assumes that an application supported by the RDM will exercise reasonably strong authentication of each end-user.
Each Location can be linked to any number of entries in the Group_right table, each specifying a group_id and an access_right defining the level of access allowed by that group of users to that Location.
Access Methods
The RDM can contain all the technical information necessary to an application to describe how the resource collections at certain types of Location can be accessed, or searched to disclose the individual (‘atomic’) items within them that match some user criteria. An application using the RDM (such as the HeadLine PIE) can use this metadata to allow a single search query to be directed at multiple heterogeneous targets in parallel, and can then collate and present all the search result-sets. The field Location.search_protocol, if specified, indicates that a Location record has a linked record in one of the following protocol-specific tables: location_z3950, location_whoispp, location_www or location_sql. These each link to subsidiary records in other protocol-specific tables, for specifying the mapping of queries from a generic format, and the mapping of result-sets received back to a generic format.
This parallel searching was not originally an objective of the HeadLine project (it has been the primary focus of other eLib Programme projects, such as M25 Link [http://www.m25lib.ac.uk/M25link/], but was thought by the end-users we consulted to be an ‘obvious’ feature necessary in an interface like the PIE. It has so far been implemented in prototype form for Z39.50 and Whois++ targets, with interfaces to other SQL-compliant resource databases and Web search-engines currently under development. Although very few ‘traditional’ library resource catalogue targets support SQL, it was included as a protocol partly to ensure a route for RDM-based collection-level databases to interoperate with each other.
The details of these elements of the RDM will be documented in detail in a future paper on interoperability features of the RDM.
Attributes and conventions common to several RDM tables
Time-stamps
All dates (or times) in the RDM are held as 14 character text fields, in the form YYYYMMDDHHMMSS. A date-time of 2.30pm on the 5th of March 2001 would be held as the string: “20010305143000”. Where less precision is required or appropriate, insignificant parts of the field can be filled with zeroes.
Maintenance administration
The Resource, Location, and Supplier tables each contain a standard set of 4 attributes: ad_creator_persid, ad_create_time, ad_last_mod_persid, ad_last_mod_time. These are updated automatically by access routines, to assist in tracking changes to the database with the identities of the original creator of a record and the person to update it most recently, with the date/time of each event. Maintainer and manager identities (xxx_persid) are normally recorded as standard format email addresses, like: “j.paschoud@lse.ac.uk”.
The Resource and Location tables each additionally contain a timestamp field ad_last_checked_time for use by automatic maintenance processes that will periodically check that URLs in these records are still reachable (alerting a human maintainer if not).
References
- [Graham] Graham, Stephen; “The HeadLine Resource Data Model” in VINE, Issue 117, pages 13-17.
- [SQL] ISO/IEC 9075:1992, “Information Technology — Database Languages — SQL” (available from: American National Standards Institute, or see http://www.jcc.com/SQLPages/jccs_sql.htm for useful, but unofficial references)
- [Hamilton] Hamilton, Martin; Archived message to the ROADS discussion list on 3rd May 2000 http://www.roads.lut.ac.uk/lists/open-roads/2000/05/0000.html
- [McLeish] McLeish, Simon; “The user environment in the hybrid library” in Managing Information, (September 1999) Vol 6 (7);
- http://www.aslib.co.uk/man-inf/sep99/articles.html
- [Gambles] Gambles, Anne; “The development and launch of the HeadLine Personal Information Environment” in Information Technology and Libraries (December 2000) Vol 19 (4) pages 199-205; http://www.lita.org/ital/ital1904.html
- [Rusbridge] Rusbridge, Chris; “Towards the Hybrid Library” in D-Lib, July/August 1998; http://www.dlib.org/dlib/july98/rusbridge/07rusbridge.html
- [Morgan] Morgan, Eric Lease; “MyLibrary: A Model for Implementing a User-centered, Customizable Interface to a Library’s Collection of Information Resources”, February 1999; http://my.lib.ncsu.edu/about/paper/
- [Paschoud] Paschoud, John; “All Users are Not Created Equal! - How to decide Who Gets What from your Hybrid Library”, 30th March 1999 paper in the eLib session at Internet Librarian International 1999; http://www.headline.ac.uk/public/diss/index.html#90330JP
- [Noble] Noble, Imelda; “Editing the Headline Resource Database using Access” (unpublished, internal project document)
- [ExLibris] Supplier product information on MetaLib http://www.aleph.co.il/MetaLib/overview.html
- [EASI] http://www.library.lse.ac.uk/services/guides/easi.html
- [Microsoft] Supplier product information on ODBC http://www.microsoft.com/data/odbc/default.htm
- [RSLP] Research Support Libraries Programme, Collection Level Description http://www.ukoln.ac.uk/metadata/cld/
Author Details
|
Article Title: “The filling in the PIE - HeadLine’s Resource Data Model”
Authors: John Paschoud
Publication Date: 23-Mar-2001
Publication: Ariadne Issue 27
Originating URL: http://www.ariadne.ac.uk/issue27/paschoud/intro.html