The JISC Information Environment and Web Services
The JISC Information Environment
The Distributed National Electronic Resource (DNER) [1] is a JISC-funded, managed, heterogeneous collection of information resources and services (bibliographic, full-text, image, video, geo-spatial, datasets, etc.) of particular value to the further and higher education communities. The JISC Information Environment (JISC IE) [2] is the set of networked services that allows people to discover, access, use and publish resources within the DNER. The JISC IE technical architecture [3] specifies the standards and protocols that provide interoperability between this network of services.
The current version of the JISC IE architecture focuses on the discovery of and access to resources within the DNER. It is not the intention of this article to provide a detailed description of the architecture. However, the following overview will allow us to make some comparisons between the JISC IE and emerging architectures based on Web services.
The architecture suggests a three-layer model comprising a provision layer, a fusion layer and a presentation layer. The intention is to allow service providers within the JISC IE to work together to provide more seamless services than are possible currently. In part, the intention is to reduce the need for end-users to interact with multiple, different Web sites in order to discover, access and use resources that are of interest to them.
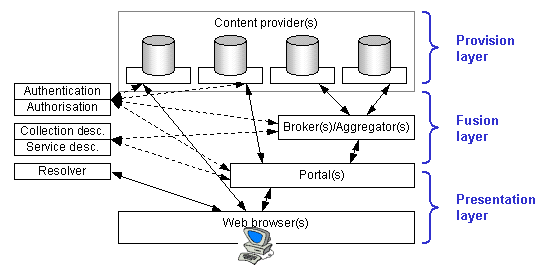
Figure 1 - JISC IE architecture
Content providers
In the provision layer, content providers make resources available (typically as part of their Web sites). Perhaps the most obvious content providers in the JISC IE are those hosted by the JISC-funded data centres and other JISC-funded services [4]. There are, of course, many other content providers, both within and without the UK academic community. Indeed, calls like the recent JISC FAIR programme [5], have explicitly encouraged UK HE and FE institutions to see themselves as content providers within the JISC IE.
Portals
In the presentation layer, portals provide the end-user with discovery services across multiple content providers. To support this, content providers must disclose information about the resources they hold in order that portals can provide discovery services across that content. It is worth noting that a number of different types of portal are likely to emerge. These include the subject portals being developed by the RDN through the Subject Portals Project [6], portals based on media type (e.g. an image portal) and institutional portals.
The architecture suggests that content providers disclose metadata about the resources they hold in one of three ways. They can make their metadata available for searching (i.e. allow portals to send search queries to them, returning appropriate matches in their databases). They can make their metadata available for harvesting (i.e. allow other services to download copies of their metadata records). Finally, they can alert other services to the existence of new resources.
The JISC IE architecture specifies that the Bath Profile of Z39.50 [7] be used as the mechanism for supporting distributed searching, that the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) [8] be used to support metadata harvesting and that RDF Site Summary (RSS) [9] be used to support alerting. It is worth noting the similarities between these three standards. They are all XML based (or partially XML-based in the case of functional area C of the Bath Profile of Z39.50) and they all support the exchange of metadata based on unqualified Dublin Core. Portals and content providers interact using these three mechanisms.
Presentation layer functionality may be shared between the portal and the end-user’s Web browser. For example, a saved search may be stored at the portal as part of the user’s profile. Alternatively, it may take the form of a URL that can simply be added to the user’s bookmarks stored in the browser. Similarly, display preferences may be applied by the portal software prior to the delivery of HTML to the browser, or they may be applied within the browser, in the form of a Cascading Style Sheet.
Brokers and aggregators
A middle layer - the fusion layer - sits between the provision layer and the presentation layer. This layer is responsible for combining metadata records from one or more content providers, as a result of cross-searching, harvesting or alerting. Some fusion activity may be undertaken directly by portals and content providers. In other cases, stand-alone fusion services may be developed. In the case of cross-searching, such stand-alone services are typically referred to as brokers. In the case of harvesting and alerting, such services are referred to as aggregators. An example broker is the one being developed by the Xgrain project [10] to enable “cross-searching between Z39.50-compliant abstracting and indexing, and tables of contents, services”.
Services in the fusion layer may combine the harvesting and distributed searching approaches. For example, a fusion service may gather metadata records from content providers using the OAI-PMH, and make the combined database of gathered records available for searching using Z39.50.
Resolvers
The technologies described above facilitate the discovery of resources by end-users and address what has been termed the portal problem - namely, how do you provide seamless discovery services across a range of disparate content providers. However, discovering the existence of a resource may only be the first part of the problem faced by end-users. The primary reason for discovering a resource is to gain access to it, i.e. to get a copy of the resource onto their physical or virtual desktop. In some cases, notably that of freely available Web resources, access is provided by simply clicking on the link - the URL in the metadata record takes the end user directly to the resource. (Note that in a separate article in this issue, Brian Kelly provides some guidelines for making resource URIs more persistent). In other cases, particularly in the case of discovering books, journals and journal articles, there needs to be a mechanism for linking from the discovered metadata record to the most appropriate copy of the resource. This is known as the appropriate copy problem. There is no need to take a specific view about what appropriate means here, however obvious examples include the physical copy of the resource that is held in the end-user’s local library, the online copy for which the user (or the user’s institution) has a licence agreement, the copy that can be delivered fastest, the copy available from the user’s preferred delivery service and so on. It is worth noting that, for any given end-user, the most appropriate copy of a resource may change as they move from accessing the Internet in their office on campus, to accessing the Internet at home, to accessing the Internet while abroad at a conference.
The JISC IE architecture specifies the use of OpenURLs [11] and OpenURL resolvers to support access to the most appropriate copy of a resource. OpenURLs were described in some detail in a previous issue of Ariadne [12]. Briefly, an OpenURL is a URL that carries a citation (some metadata) for a resource and passes that information to an OpenURL resolver specified by the end-user. In the future we might expect to see an increasing number of institutions offering their own OpenURL resolvers based on commercial offerings such as SFX from ExLibris [13]. In the meantime however, it may be necessary to run a national service, offering an OpenURL resolver for those members of institutions with no appropriate resolvers of their own. The kind of work being undertaken by the JOIN-UP programme[14] might form the basis for such a national service.
Mapping the service landscape
We can see from the above that there will be a range of interactions between service components in the JISC IE in order to support the delivery of discovery and access functionality to the end-user. The key services that need to interact with each other include the portals, content providers, brokers, aggregators and resolvers described above. However, there will also be a whole range of other shared services that need to be considered and that haven’t been described here. These include authentication and authorisation services such as Athens [15], terminology services, metadata schema registries, index services, institutional profiling services, user-personalisation services and so on.
Service components will need access to descriptions of the other components that are available to them. Furthermore, such descriptions will need to be at a detailed enough level to support machine-to-machine (m2m) interaction between components.
The JISC IE architecture currently refers to two complementary services called the collection description service and the service description service. The collection description service was seen as providing descriptions of the content of the collections made available by content providers in the DNER. The service description service was seen as providing detailed, protocol level, information about the access points to the collections described in the collection description service. Note that there is not necessarily a 1:1 mapping between these descriptions - for example, a single DNER collection may be offered as both a Z39.50 target and an OAI repository.
Despite being logically separated, it was always envisaged that the collection description and service description services might be offered in a combined form.
Web services
In an article in Ariadne 29, Tracy Gardner provided a good introduction to the concept of Web services [16]. A broad definition of Web services is given in the IBM Web services tutorial [17]:
Web services are a new breed of Web application. They are self-contained, self-describing, modular applications that can be published, located, and invoked across the Web. Web services perform functions, which can be anything from simple requests to complicated business processes.
It is interesting to note that all the JISC IE service components described above can be thought of as Web services given this definition, though some might argue that making this case for Z39.50 is a little extreme!
However, the definition of Web services provided by the W3C [18] is a little narrower:
The advent of XML makes it easier for systems in different environments to exchange information. The universality of XML makes it a very attractive way to communicate information between programs. Programmers can use different operating systems, programming languages, etc, and have their software communicate with each other in an interoperable manner. Moreover, XML, XML namespaces and XML schemas serve as useful tools for providing mechanisms to deal with structured extensibility in a distributed environment, especially when used in combination.
The same way programmatic interfaces have been been available since the early days of the World Wide Web via HTML forms, programs are now accessible by exchanging XML data through an interface, e.g. by using SOAP Version 1.2, the XML-based protocol produced by the XML Protocol Working Group. The services provided by those programs are called Web services.
Here we can see a rather more definite link between Web services and the use of XML, XML namespaces and XML schemas. Given this definition it is rather harder to make the case for the current form of Z39.50 to be considered a Web service. Nonetheless, the OAI-PMH and the use of RSS over HTTP certainly do fall well within these definitions.
The ongoing work on ZiNG [19] and in particular SRW [20], looks to be of interest here. SRW is a protocol that will offer a subset of Z39.50 functionality based on XML and SOAP [21]. The development of technologies like SRW complements the existing use of the OAI-PMH and the Bath Profile of Z39.50 quite nicely, and we would expect it to feature in future revisions of the JISC IE architecture if and when it becomes more stable.
The Gardner article describes IBM’s Web services architecture [22], comprising a service requestor, a service provider and service registry. The services offered by the service provider are described using the Web Service Description Language [23], with descriptions made available through the service registry. Universal Discovery, Description and Integration (UDDI) [24] provides a technology for building distributed registries of Web services.
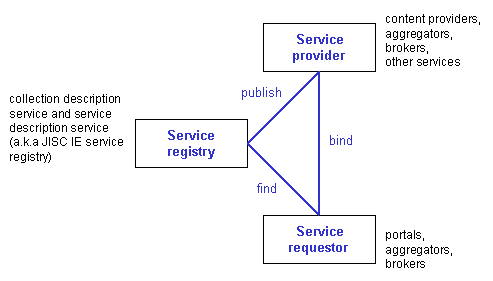
Figure 2 - Web services architecture
By turning this model on its side (with the requestor at the bottom, the provider at the top and the registry to the left) it is easy to see how the Web services architecture layers onto the current JISC IE architecture diagram above. Between any two points in the architecture (portal and broker, aggregator and content provider, portal and content provider, etc.) there is the triangular model made up by those two service components and the combined collection and service description service. There is some logic in re-naming such a combined directory service as the JISC IE service registry.
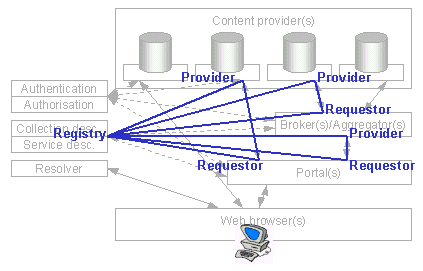
Figure 3 - JISC IE and Web services
A recent study by Matthew Dovey [25], considers the possibilities for using WSDL and UDDI as the basis for service description within the JISC IE, albeit acknowledging the need to provide access to richer collection descriptions within or alongside these technologies.
From portals to portlets - the service landscape gets more complex!
As a final thought, it is worth mentioning the current trend towards implementing portals using portlet technologies. Portlets provide the building blocks for portals and feature heavily in many of the current portal building frameworks such as the Apache Jetspeed project [26], IBM’s WebSphere Portal Server [27] and Oracle’s Application Server Portal [28]. Portlets provide the visible components end-users see within portal pages. Typically, each portlet offers a small chunk of functionality, such as a cross-search or the display of a news channel.
The RDN Subject Portals Project is adopting a portlet approach for the development of the RDN subject portals. There are clear synergies between portlets and Web services and it is reasonable to expect that, in many cases, the functionality offered within a portlet will be built on an equivalent underlying Web service. The big advantage of a portlet approach is that the chunks of functionality offered by the subject portals will, in theory, be available for embedding directly into institutional portal developments. Goodbye monolithic portal applications - hello modular, re-usable portlets!
However, there is a cost to this approach - the need for the portal to have some knowledge about the portlets that are available to it, some of which will be local to the portal, some of which will be remote. Portlets will form a whole new set of services that will need describing in order that they can be discovered by portals, and portal developers, administrators and users.
Conclusion
This article has attempted to summarise the JISC IE architecture and compare it with emerging Web services architectures. Although Web services are being carried along on a near tidal wave of new technologies and acronyms, the underlying concepts aren’t that different to those already in place.
There has been a tendency, at least in some parts, to see the use of Z39.50 in the JISC IE architecture as an indication that the architecture is not mainstream enough. We would disagree - Z39.50 appears in the architecture because there is no practical alternative open protocol available at the moment to support distributed searching. But that is likely to change, and as new distributed search technolgies are developed they can be added to the JISC IE architecture.
What is perhaps more important, is whether there is a need to align the JISC IE architecture more fully with architectures based on Web services. Such an alignment will set the JISC Information Environment firmly within the more general architectural frameworks being developed to support commercial portal activities and other business-to-business (b2b) service scenarios. We have tried to demonstrate in this article that such an alignment does not require a drastic change to the current architecture.
References
- The Distributed National Electronic Resource (DNER)
<http://www.jisc.ac.uk/dner/> - Information Environment: Development Strategy 2001-2005 (Draft)
<http://www.jisc.ac.uk/dner/development/IEstrategy.html> - JISC Information Environment Architecture
Andy Powell & Liz Lyon, UKOLN, University of Bath
<http://www.ukoln.ac.uk/distributed-systems/dner/arch/> - JISC Services
<http://www.jisc.ac.uk/services/index.html#info> - JISC Circular 1⁄02 - Focus on Access to Institutional Resources Programme (FAIR)
<http://www.jisc.ac.uk/pub02/c01_02.html> - Subject Portals Project
<http://www.portal.ac.uk/spp/> - The Bath Profile Maintenance Agency
<http://www.nlc-bnc.ca/bath/bath-e.htm> - The Open Archives Initiative
<http://www.openarchives.org/> - RDF Site Summary (RSS) 1.0
<http://purl.org/rss/> - Xgrain
<http://edina.ed.ac.uk/projects/joinup/xgrain/> - OpenURL Overview
<http://www.sfxit.com/openurl/> - OpenResolver: a Simple OpenURL Resolver
Andy Powell, UKOLN, University of Bath
<http://www.ariadne.ac.uk/issue28/resolver/> - SFX - Content-sensitive Reference Linking
<http://www.sfxit.com/> - The JOIN-UP Programme
<http://edina.ed.ac.uk/projects/joinup/> - Athens Access Management System
<http://www.athens.ac.uk/> - An Introduction to Web Services
Tracy Gardner, IBM United Kingdom Laboratories (Hursley)
<http://www.ariadne.ac.uk/issue29/gardner/> - Web services – the Web’s next revolution
<http://www-105.ibm.com/...OpenDocument> - W3C Web Services Architecture Working Group Charter
<http://www.w3.org/2002/01/ws-arch-charter> - Z39.50-International: Next Generation
<http://www.loc.gov/z3950/agency/zing/zing.html> - Search/Retrieve Web Service
<http://www.loc.gov/z3950/agency/zing/srw.html> - Simple Object Access Protocol (SOAP) 1.1
<http://www.w3.org/TR/SOAP/> - IBM Web services Conceptual Architecture
<http://www-4.ibm.com/software/solutions/webservices/pdf/WSCA.pdf> - Web Services Description Language (WSDL) 1.1
<http://www.w3.org/TR/wsdl> - uddi.org
<http://www.uddi.org/> - JISC Information Environment Service Level Descriptions
Matthew Dovey, Oxford University
<http://www.ukoln.ac.uk/distributed-systems/dner/arch/service-description/study/> - The Jakarta Project - Jetspeed
<http://jakarta.apache.org/jetspeed/site/> - IBM WebSphere Portal Server Architecture
<http://www-3.ibm.com/software/webservers/portal/architect.html> - Oracle9i Application Server Portal - Product Features
<http://portalstudio.oracle.com/.../PORTAL_TWP_9_01.PDF>
Author details
Andy Powell
UKOLN
University of Bath
a.powell@ukoln.ac.uk
Liz Lyon
UKOLN
University of Bath
e.j.lyon@ukoln.ac.uk