Windows Explorer: The Index Server Companion
Microsoft’s Index Server is a service supplied with the Windows NT 4.0 Server and Windows 2000 Server products. The service indexes HTML and other content residing on the file system. These indexed files may be queried using a number of techniques, but of particular relevance to web developers is the ability to build completely customised search facilities based on Active Server Pages (ASP) by making use of Index Server’s Component Object Model (COM) objects.
A limitation to Index Server is that it can only be used to index files via the file system. Furthermore, integrating file and database searches isn’t always straightforward. This article looks at how the Index Server Companion overcomes these limitations, enabling Index Server and ASP to form the basis of some sophisticated web applications.
An Overview of Index Server
Index Server is one of Microsoft’s most useful server products. On the administrative side of things, it is easy to install, performance while indexing content is good, and once installed maintenance tasks for the systems administrator are minimal. The development of customised search applications using ASP is also made fairly straightforward through the use of the Query and Utility server components [1].
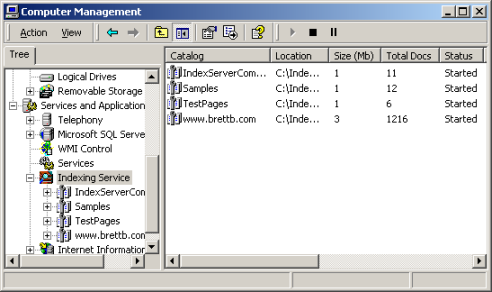
Figure 1. Index Server is administered through an easy to use interface
The main limitation of Index Server is that it can really only be used to index content hosted on servers on the same machine (or network) as the machine hosting the Index Server service. Although it is possible to set up a share to a Unix or Linux web server using a file sharing solution such as SAMBA, this isn’t always satisfactory because Index Server is not case sensitive with respect to filenames, so this can cause problems when displaying search results. The Apache web server’s spelling module, modspelling [2] can correct some case-sensitivity issues, but not all servers will have this module installed.
Added to this problem is the fact that organisations such UK academic institutions will often have web content distributed over a number of web servers that may be hosted on a number of different operating systems. For example, the University of Essex where I once worked had at least 15 web servers with a substantial amount of content hosted on them, and it isn’t by any means the largest University in the country.
Another issue is that it can be a chore to prevent Index Server from indexing certain content. Since it indexes the file system, it has no concept of the Robots Exclusion Standard specification’s robots.txt files [3]. It also has no concept of the ‘robots’ meta tag. Although Index Server can be prevented from returning files with specific filenames and/or paths, it can get quite fiddly, as can be seen from this example from the search facility of my personal website:
” AND NOT #path ASPAlliance AND NOT #path ** AND NOT #path download AND NOT #path images AND NOT #path adm AND NOT #path backgrounds AND NOT #path dbase AND NOT #path test AND NOT #path script AND NOT #filename *.class AND NOT #filename *image.asp AND NOT #filename *.asa AND NOT #filename *.css AND NOT #filename redirect.asp AND NOT #filename *postinfo.html AND NOT #filename readme“
Finally, an increasing amount of data accessible via the Internet is stored in databases rather than HTML. A comprehensive search facility should ideally return search results from both static HTML content as well as content stored in databases.
Extending the Functionality of Index Server
Retrieving and indexing content from a web server by use of a web robot solves many of the problems Index Server has. The web robot is able to mimic a web browser, starting at one page in the site and traversing the links in the site until it has retrieved all of the pages of the site. The robot will potentially be able to retrieve content from any web server, regardless of the platform it is hosted on. Two products that allow you to do this are Microsoft’s Site Server 3.0 and the author’s own Index Server Companion.
Microsoft Site Server 3.0
Microsoft’s Site Server 3.0 software suite has a Search application that enhances Index Server by allowing you to (amongst other things) retrieve and index content from remote websites using an integrated web robot. For an overview of Site Server 3.0 Search, take a look at a previous article on Ariadne [4]. Unfortunately Site Server 3.0 Search has a few shortcomings, including:
- Site Server 3.0 isn’t the easiest of applications to install, especially if SQL Server is installed on the same machine.
- The product wasn’t designed for Windows 2000 Server.
- It is no longer in active development.
- Few third party hosting companies support Site Server 3.0.
- Even with academic licensing discounts, Site Server 3.0 costs a lot of money, which cannot always be justified if you only want to use the Search application of the software suite.
Index Server Companion
The Index Server Companion is a cost effective method of retrieving content from remote webservers for Index Server to index. Furthermore it also allows retrieval of content from ODBC databases which can be subsequently indexed by Index Server.
Features of the Index Server Companion
The main features of the Index Server Companion are:
- Enables Index Server to allow searching of potentially any web server or ODBC compliant database.
- Integrated web robot extracts content from websites. Includes support for robots.txt files and robots meta tags. Robot can negotiate sites using HTML Frames. An optional mode allows Query Strings to be treated as distinct URLs (e.g. treat http://www.aspalliance.com/brettb/WebJobMarket.asp?Skill=ASP as being a distinct URL from http://www.aspalliance.com/brettb/WebJobMarket.asp?Skill=JSP).
- Ability to retrieve binary files from servers, including Adobe Acrobat PDF, Microsoft Office documents and even images.
- Support for full or incremental project updates of both web and database content, meaning that Index Server only has to re-index content that has changed.
- Configuration of the Index Server Companion is through the editing of a plain text configuration file.
- Index Server Companion can be run from the command line, and scheduled using the Windows Task Scheduler.
- Full reporting of activity to an external plain text log file.
- Flexible output options mean that administrative access to Index Server is not necessarily required.
- Fully documented VBScript examples show how to make use of the Index Server Companion in ASP pages.
- Detailed documentation in Microsoft’s HTML Help format.
- Fully documented source code.
- Access to product updates and technical support.
Figure 2. The Index Server Companion contains fully searchable documentation in Microsoft’s HTML Help format
System Requirements
The Index Server Companion is written in Perl 5 for Windows NT or 2000. Although any version of Perl 5 could potentially be used to run the ASP Documentation Tool, it has been specifically developed using ActiveState’s ActivePerl. ActivePerl is available as a free download from the ActiveState website [5].
It also requires a server running either Index Server on Windows NT 4.0 Server, or the Indexing Service on Windows 2000. The Index Server Companion does not have to be run from the machine on which the Index Server is installed.
Configuring and Running the Index Server Companion
The Index Server Companion is a Perl script that needs to be run from the Windows command line. There is a single mandatory parameter, which tells the script which configuration file to use. So to run the Index Server Companion for the Sample Project, an MSDOS Command Prompt is opened in the folder where the Index Server Companion files are installed installed and the following is typed:
IndexServerCompanion.pl –c=“SampleProject/SampleProject.ini”
It is of course possible to run the Index Server Companion from .bat scripts, which can then be scheduled using the AT command or the Windows Task Scheduler. This makes it straightforward to update the Index Server’s index of website and database content at specific times and frequencies.
The configuration file is a plain text file containing a number of settings. A sample configuration file is shown below:
[ProjectName] = ASPArticles
[CreateLogFile] = yes
[LogFileDir] = Samples/ASPArticles/Logs
[InfoStoreDir] = Samples/ASPArticles/InformationStore
[OutputDir] = Samples/ASPArticles/Output
[Verbose] = yes
[StartURL] = http://www.aspalliance.com/brettb/Default.asp
[BaseURL] = http://www.aspalliance.com/brettb/
[UserAgent] = Index Server Companion 1.1 (admin@server.com)
[UseRobotsTextFile] = yes
[UseRobotsMetaTag] = yes
[UseURLQueryStrings] = no
[CrawlType] = incremental
[MaxURLSize] = 1024
[MaxNumberOfURLs] = 4096
[URLExtensions] = .htm .html .asp .aspx .jsp .php .cfm
[FileExtensions] = .doc .pdf .rtf
[AddURLToTitle] = yes
[CaseSensitiveServer] = no
[AddRowToTitle] = no
[RefreshAllRows] = no
The Index Server Companion is supplied with full documentation in Microsoft’s HTML Help format that describes each of the configuration settings.
When the script is run, the Index Server Companion will display details of its status in the Command Prompt window. A detailed log file is also created.
How the Index Server Companion Works
The Index Server Companion script contains a fully functional web robot that is able to extract the content from all of the required pages of the specified website. It contains support for the Robots Exclusion Standard specification [3], and support for the robots meta tag contained within individual pages. Each file extracted from the website is modified to contain a special meta tag that give the original URL (for web content). It is then saved to disk from where it can be indexed by Index Server. The contents of these special meta tags can then be used by the ASP page displaying the results of a web search, so that clicking on a search result item will display the original URL. Unfortunately Index Server will not allow you to retrieve the content from custom meta tags without making a minor modification in the Index Server’s Microsoft Management Console (MMC), so there is also a special mode in the Index Server Companion that appends the original URL into the page’s HTML <title> tag.
Searching Web Content with the Index Server Companion
Index Server Companion allows content from remote websites to be retrieved and consequently indexed by Index Server. A working example of this may be seen [6]. This is a search page running on Internet Information Server 4.0 (Windows NT 4 Server) that allows you to search my ASPAlliance site, together with the articles I have written for Ariadne.ac.uk and ASPToday.com. Since I don’t have administrative access to the Index Server on the machine hosting the search page, I have used the feature of the Index Server Companion that allows the document’s original URL to be appended to the original title. For example the <title> tag of the ASPToday article “ASP Documentation Systems” at http://asptoday.com/content.asp?id=1435 is modified in the file saved to read:
<title>ISC_URL=http://asptoday.com/content.asp?id=1435 ASP Documentation Systems</title>
The URL and original title are separated by a tab character. The search results page then contains a small piece of ASP code to split this title back into the article’s URL and original title:
<%
‘Extract the document’s URL and title
If Instr(oRS(“doctitle”), “ISC_URL”) > 0 Then
‘Split the doctitle at a tab character
DocumentInformation = Split(oRS(“doctitle”), chr(9))
‘The document’s URL is the first item in the array
sDocumentURL = DocumentInformation(0)
‘Remove the “ISC_URL=” text in the document URL
sDocumentURL = Replace(sDocumentURL, “ISC_URL=“, “”)
‘The document’s title is the second item in the array
sDocumentTitle = DocumentInformation(1)
End If
%>
The entire ASP code for the sample search page is available online [7].
Searching Binary Files with the Index Server Companion
Index Server is able to index content from a range of non-HTML content. This includes Microsoft Office documents, and once Adobe’s IFilter is installed, Adobe Acrobat PDF files. The Index Server Companion is able to retrieve any binary files that it may encounter while crawling a website. A configuration option specifies which binary file types are retrieved. The filenames of the saved files are modified to include the original URL in the filename. So for example, the Adobe Acrobat PDF document at:
Will be saved with the filename:
- Ohttp^c^b^bwww.aspalliance.com^bbrettb^bdownloads^bTheIndexServerCompanion.pdf
If the file appears in search results, the original URL can be retrieved using the following ASP VBScript:
<%
‘Extract the URL for other files (e.g. PDF and DOC files)
If Left(oRS(“FileName”), 2) = “o” Then
sDocumentTitle = oRS(“doctitle”)
sDocumentURL = CreateURLFromFileName(oRS(“FileName”))
End If
%>
The CreateURLFromFileName function will return the original URL:
<%
‘Non-HTML files like Adobe Acrobat PDF files and Word
‘documents are stored with their original URLs partially
‘encoded in their filenames. This function will return the
‘original URL of the file.
‘The encoding done by the Index Server Companion removes
‘characters that cannot be present in Windows filenames
’(these are: \/:?”<>|)
Function CreateURLFromFileName(FileName)
‘Remove o_ prefix from URL
FileName = Mid(FileName, 3, Len(FileName) - 2)
‘Remove other encoded characters
FileName = Replace(FileName, “^f”, “\“)
FileName = Replace(FileName, “^b”, “/”)
FileName = Replace(FileName, “^c”, “:“)
FileName = Replace(FileName, “^s”, “”)
FileName = Replace(FileName, “^q”, “?”)
FileName = Replace(FileName, “^d”, Chr(34))
FileName = Replace(FileName, “^l”, “<”)
FileName = Replace(FileName, “^g”, “>”)
FileName = Replace(FileName, “^p”, “|”)
CreateURLFromFileName = FileName
End Function
%>
Unfortunately Index Server stores the URLs of other files as lower case, but a workaround will hopefully be included with the next release of the Index Server Companion.
URLs with Query Strings
There is an option within the Index Server Companion to treat URLs containing Query Strings as distinct URLs. This means that it is possible to index custom built web applications that use the Query String to store data. For example, if an online phone book application had a form that allowed the user to search for users by forename, surname and department, the search results page for a specific user might be accessed using the URL:
http://www.awebsite.ac.uk/phonebook/showresults.php?forename=John&surname=Smith&dept=Law
The entire phone book could be indexed by the Index Server Companion if it was presented with a start page containing a hyperlink to every user. The advantage of this is that users would be able to see search results of people as well as other content in an integrated search results page. There may also be performance benefits, as searching LDAP directories can often be very time consuming, whereas Index Server returns search results almost instantaneously.
Searching Databases with the Index Server Companion
The Index Server Companion is able to index content from database tables, queries (Microsoft Access) and stored procedures (SQL Server). Database connectivity is achieved through the use of Open Database Connectivity (ODBC), the technology that allows Microsoft Windows to transparently connect to any database that has an ODBC driver. Microsoft Access and SQL Server naturally have ODBC drivers, as do many non-Microsoft databases such as Oracle and FileMaker Pro.
It is of course possible to search databases using Structured Query Language (SQL), but by making use of Index Server Companion, it is possible to integrate database searches with search results from web page searches. There are also other advantages: Index Server contains sophisticated pattern matching syntax, and it is a lot faster at returning search results than an equivalent SQL statement would be when using a database such as Microsoft Access.
The Index Server Companion makes it possible for Index Server to index databases by retrieving the rows of a specified database table and creating an HTML file containing the data from a specific database row. Index Server can then be used to index these HTML files. In search results pages, it is possible to extract the details of the table and row from which the data originated, so that the search results page can be modified to point to the original database data. A sample page produced from the SQL Server sample pubs database is shown below:
<html>
<head>
<meta name=”ISC_title_id” content=”MC2222“>
<meta name=”ISC_title” content=”Silicon Valley Gastronomic Treats“>
<meta name=”ISC_type” content=”mod_cook “>
<meta name=”ISC_price” content=”19.99“>
<meta name=”ISC_pubdate” content=”6/9/1991 12:00:00 AM“>
<meta name=”ISCnotes” content=”Favorite recipes for quick, easy, and elegant meals.“>
<meta name=”description” content=”Favorite recipes for quick, easy, and elegant meals.“></head>
<title>Silicon Valley Gastronomic Treats</title>
<body>
</body>
</html>
In this example, the value of the title table column is optionally used to give the page an HTML title tag, and the notes table column is used for the description meta tag. Each of the custom ISC prefixed meta tags can be queried using Index Server, although to retrieve their contents a minor configuration change to Index Server is required.
The Index Server Companion can also modify the HTML’s <title> tag to include the table name and row ID, e.g.:
<title>ISC_Table=titles ISC_KeyField=title_id ISC_RowNumber=MC2222 Silicon Valley Gastronomic Treats</title>
The following ASP code shows search results for database rows where the ISC_type meta tag (and hence the type column) is “mod_cook”:
<%@ Language=VBScript %>
<%
Dim oQuery
Dim sDataRow
Dim sDataRow_Table
Dim sDataRow_Keyfield
Dim sDataRow_RowNumber
Dim sDataRow_RowTitle
Dim sQueryText
sArticlesPath = “Titles_Simple\SampleContent“
sQueryText = “#path ” & sArticlesPath & “ AND NOT #path _vti “
‘Search for content in the specified folder which also have the isc_type meta tag equal to “mod_cook”
sQueryText = sQueryText & “ AND @isc_type mod_cook”
Const SEARCH_CATALOG = “www.brettb.com”
Set oQuery = Server.CreateObject(”IXSSO.Query”)
‘A column must be defined for each custom meta tag that is returned in the search
‘results RecordSet
oQuery.DefineColumn “isc_type (DBTYPE_WSTR) = d1b5d3f0-c0b3-11cf-9a92-00a0c908dbf1 isc_type”
oQuery.Catalog = SEARCH_CATALOG
oQuery.Query = sQueryText
oQuery.MaxRecords = 200
oQuery.SortBy = “rank[d]”
oQuery.Columns = “vpath, doctitle, FileName, Path, Write, Rank”
Set oRS = oQuery.CreateRecordSet(“nonsequential”)
%>
<HTML>
<HEAD>
<META NAME=“GENERATOR” Content=“Microsoft Visual Studio 6.0”>
</HEAD>
<BODY>
<%
If oRS.EOF Then
Response.Write “No pages were found for the query <i>” & sSearchString & “</i>“
Else
Do While Not oRS.EOF
If Instr(oRS(“doctitle”), “ISC_Table”) > 0 Then
sDataRow = Split(oRS(“doctitle”), chr(9))
sDataRow_Table = sDataRow(0)
sDataRow_Keyfield = sDataRow(1)
sDataRow_RowNumber = sDataRow(2)
sDataRow_RowTitle = sDataRow(3)
sDataRow_Table = Replace(sDataRow_Table, “ISC_Table=“, “”)
sDataRow_Keyfield = Replace(sDataRow_Keyfield, “ISC_KeyField=“, “”)
sDataRow_RowNumber = Replace(sDataRow_RowNumber, “ISC_RowNumber=“, “”)
End If
Response.write “<b>Database Table:</b> “ & sDataRow_Table & “<br>“
Response.write “<b>Database Key Field:</b> “ & sDataRow_Keyfield & “<br>“
Response.write “<b>Database Row Number:</b> “ & sDataRow_RowNumber & “<br>“
Response.write “<b>Database Row Title:</b> “ & sDataRow_RowTitle & “<br>“
‘Construct a URL that can be used to view the database data
Response.write“<b>View Row URL:</b> <a href=““DisplayData.asp?ID=” & sDataRow_RowNumber & “””>” & sDataRow_RowTitle & “</a><br>“
%><hr><%
oRS.MoveNext
Loop
End If
%>
</BODY>
</HTML>
<%
Set oRS = nothing
Set oQuery = nothing
%>
The disadvantage to using the Index Server Companion to index databases is that it cannot really be used for data that changes frequently, or for very large amounts of data. In these kinds of situations it is possible to use more advanced techniques, such as combining Index Server and SQL search queries using the linked servers feature of SQL Server [8].
Resources
- The Index Server Companion is available for online purchase [9]. An evaluation version and the user documentation are also available.
- The colour coded and syntax highlighted ASP code in this article was created using the ASP Documentation Tool [10].
Summary and Conclusions
Index Server is a useful solution for creating website search facilities, but has a number of limitations that restrict its effectiveness. Although Site Server 3.0 Search greatly enhances the functionality of Index Server, it is expensive and no longer actively supported by Microsoft. The Index Server Companion is a low cost solution for allowing Index Server to index content from remote websites and ODBC databases, thereby assisting with the development and implementation of comprehensive website searching facilities on the Windows platform.
References
- Searching Index Server With ASP, ASPAlliance.com
http://www.aspalliance.com/brettb/SearchingIndexServerWithASP.asp - mod_speling Apache httpd module, Apache documentation
http://httpd.apache.org/docs/mod/mod_speling.html - Robots Exclusion Standard, specification
http://www.robotstxt.org/wc/norobots.html - The Microsoft Site Server Search Facility, Ariadne Issue 19
http://www.ariadne.ac.uk/issue19/nt/ - ActivePerl, ActiveState Tool Corp. website
http://www.activestate.com/ - Index Server Companion, sample search facility
http://www.winnershtriangle.com/w/Products.IndexServerCompanion.SampleSearch.asp - Index Server Companion, source code of sample search facility
http://www.brettb.com/ASPAlliance/IndexServerCompanion/Sample_Web_ASPCode.html - Creating Combined SQL Server and Index Service Queries, Avonelle Lovhaug
http://www.asptoday.com/content.asp?id=295 - Index Server Companion, website
http://www.winnershtriangle.com/w/Products.IndexServerCompanion.asp - ASP Documentation Tool, website
http://www.winnershtriangle.com/w/Products.ASPDocumentationTool.asp
Author Details
Brett spent two years working in the University of Essex Computing Service, before moving to The Internet Applications Group in the Autumn of 1999, where he developed e-Business applications for a range of corporate clients and dot-com start ups.
Brett is presently employed as an Internet developer and technical writer through his own company, Winnersh Triangle Web Solutions Limited. The company produces a number of innovative products, including the popular ASP Documentation Tool and the Index Server Companion. The company is also available for web application development, primarily using Microsoft technologies (ASP, Visual Basic, SQL Server) but also using open source technologies such as PHP, MySQL and Perl. Specialist services include development of search solutions using Microsoft’s Index Server and Site Server 3.0 Search.
As well as Ariadne, Brett has written technical articles for Wrox’s ASPToday, and ASPAlliance.com.
| Brett Burridge Web: http://www.brettb.com/ Mobile: +44 (0)7775 903972 |
Article Title: “Windows Explorer: The Index Server Companion”
Author: Brett Burridge
Publication Date: 10-Oct-2002
Publication: Ariadne Issue 33
Originating URL: http://www.ariadne.ac.uk/issue33/nt-explorer/