eBank UK: Building the Links Between Research Data, Scholarly Communication and Learning
This article presents some new digital library development activities which are predicated on the concept that research and learning processes are cyclical in nature, and that subsequent outputs which contribute to knowledge, are based on the continuous use and reuse of data and information [1]. We can start by examining the creation of original data, (which may be, for example, numerical data generated by an experiment or a survey, or alternatively images captured as part of a clinical study). This initial process is usually followed by one or more additional processes which might include aggregation of experimental data, selection of a particular data subset, repetition of a laboratory experiment, statistical analysis or modelling of a set of data, manipulation of a molecular structure, annotation of a diagram or editing of a digital image, and which in turn generate modified datasets. This newly-derived data is related to the original data and can be re-purposed through publication in a database, in a pre-print or in a peer-reviewed article. These secondary items may themselves be reused through a citation in a related paper, by a reference in a reading list or as an element within modular materials which form part of an undergraduate or postgraduate course. Clearly it will not always be appropriate to re-purpose the original data from an experiment or study, but it is evident that much research activity is derivative in nature.
The impact of Grid technologies and the huge amounts of data generated by Grid-enabled applications [2], suggest that in the future, (e-)science will be increasingly data-intensive and collaborative. This is exemplified in the biosciences where the growing outputs from genome sequencing work are stored in databases such as GenBank [3] but require advanced computing tools for data mining and analysis. The UK Biotechnology and Biological Sciences Research Council (BBSRC) recently published a Ten Year Vision [4] which describes this trend as “Towards predictive biology” and proposes that in the 21st Century, biology is becoming a more data-rich and quantitative science. The trend has clear implications for data/information management and curation procedures, and we can examine these further by returning to the concept of a scholarly knowledge cycle.
A complete cycle may be implemented in either direction so for example, discrete research data could (ultimately) be explicitly referenced in some form of electronic learning and teaching materials. Alternatively, a student might wish to “rollback” to the original research data from a secondary information resource such as a published article or from an element within an online course delivered via a Learning Management System [5]. In order to achieve this, a number of assumptions must be made which relate largely to the discovery process but are also closely linked to the requirement for essential data curation procedures. The assumptions are:
- The integrity of the original data is maintained
- There is a shared understanding of the concept of provenance
- The original dataset is adequately described using a metadata description framework based on agreed standards
- A common ontology for the domain is understood
- Each dataset and derived data and information are uniquely identified
- Open linking technology is applied to the original dataset and the derived data and information
The scholarly knowledge cycle is shown below in Figure 1.
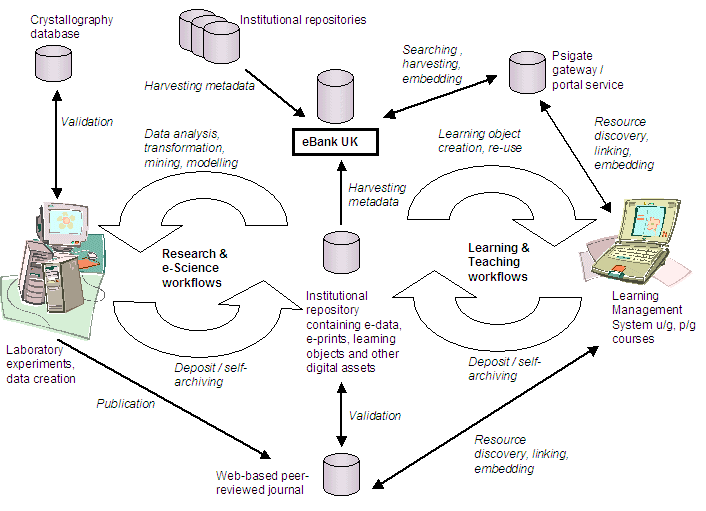
Figure 1: The Scholarly Knowledge Cycle
Illustrating by example - chemistry
We can take a closer look at some typical research information workflows which form a part of the cycle, by focusing on a discrete domain, chemistry, and in particular draw on experimental detail from the Combechem Project [6] which is an e-Science Grid-enabled initiative in the area of combinatorial chemistry investigating molecular and crystal structures. The Combechem Project is an ideal research test-bed because large quantities of varied data are generated. These include electronic lab books, crystallography data and physical chemistry data i.e. textual, numeric and 2/3D molecular structure datasets. Outputs from the project are published in fast track “Letters” formats and as articles in peer-reviewed journals. These articles reference experimental data. In addition, “Letters” are referenced in postgraduate teaching modules.
Currently, once a research experiment in this area is finished, the initial dissemination may be via a letter or communication, followed later by a more detailed explanation in a full paper describing in-depth analysis and collating several related results. Reference data may be provided at this point, but there is unlikely to be any link back to the raw or processed data. The ability to publish data directly and the wider availability of e-prints suggest that these potentially valuable connections can be made. This linking is illustrated by an example from crystallography:
- Step 1 - A new compound or material is created and submitted for structure determination by x-ray diffraction by the EPSRC National Crystallography Service [7]
- Step 2 - The data is analysed, a structure determined and then validated. At this stage an e-print system could carry the identification of the compound and the fact that a structure has been determined, supported by some basic characterisation of the material
- Step 3a - If it is found that the structure is routine and not worthy of special discussion at this stage, the full structure is made available via the e-print and submitted up to the crystallographic databases. The e-print system will link to the raw data and other researchers could look at this to assess the validity of the work
- Step 3b - If the material is worthy of discussion, then the group who produced the material will write and submit the communication to a journal. The e-print access is altered at this stage to give the referees access to the structure and the raw data. The paper can then be validated, and published, and the e-print links are opened to the community
- Step 4 - The article is referenced in an (online) course module which forms a part of the postgraduate curriculum
The eBank UK Pilot Service
eBank UK is a new JISC-funded project which is a part of the Semantic Grid Programme [8]. The project is being led by UKOLN in partnership with the Combechem project at the University of Southampton and the PSIgate [9] Physical Sciences Information Gateway at the University of Manchester. This new initiative is set in the context of the JISC Information Environment which aims to develop an information architecture [10] for providing access to electronic resources for UK higher and further education . The eBank UK pilot service is a first step towards building the infrastructure which will enable the linking of research data with other derived information.
The project will build on the technical architecture currently being deployed within the context of the ePrints UK Project [11] and which has been described in a recent Ariadne article [12]. The architecture supports the harvesting of metadata from eprint archives in UK academic institutions and elsewhere using the OAI Protocol for Metadata Harvesting (OAI-PMH) [13]. The eBank UK Project will augment this work by also harvesting metadata about research data from institutional ‘e-data repositories’. Initially this will encompass data made available by Combechem, but will include data from other sources in the longer term. Metadata records harvested from e-data repositories will be stored in the central database alongside the eprint metadata records gathered as part of the ePrints UK Project.
The eprints.org software will be adapted to provide storage for and metadata descriptions of the research data outputs. The data will be described using a schema which is based on existing work in the Combechem Project, and will be described in a human-readable document and as machine-readable XML and RDF schemas. The XML schema is required so that metadata records conforming to the schema can be exchanged using the OAI-PMH. The RDF schema will support use in the context of the Semantic Web/Grid. Recommendations are required for how e-prints should cite the research data on which they are based, and this may be achieved using a URI based on the unique identifier that is assigned to the research data when it is deposited in the e-data archive.
An enhanced end-user interface for eBank UK, targeted for delivery through the RDN PSIgate Hub, will be developed which will offer navigation from eprint metadata records to research data metadata records and vice versa. The Web interface will be hosted on the RDN Web site [14] and will form the basis of the interface that will be embedded into the PSIgate Web site. Embedding will be implemented using the CGI-based mechanism that was developed for RDN-Include [15] and by investigating development of a Web Service based on the Web Services for Remote Portlets (WSRP) [16] specification.
eBank will also investigate the technical possibilities for inferring which subject classification terms may be associated with research data, based on knowledge of the terms that have been automatically assigned to the eprints which cite those data resources.
Figure 2 below outlines the eBank UK information architecture framework under development (diagram by Andy Powell).
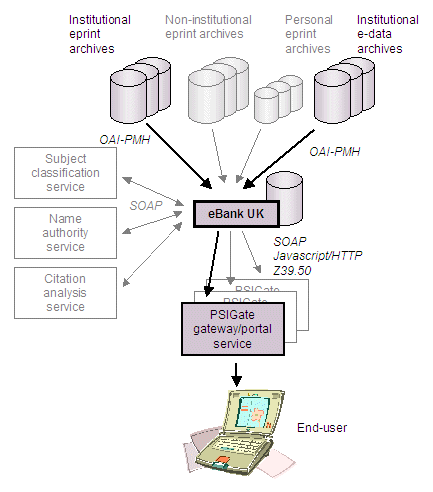
Figure 2: eBank UK Information Architecture Framework under development
Identifying the challenges
Addressing socio-economic and cultural issues
There are currently many initiatives to promote open access to the research literature through new approaches to scholarly publishing. These are based on the author self-archiving principle [17] and have focused on the creation of subject-based repositories of e-prints such as Cogprints [18] and arXiv [19], institutional repositories [20] [21] and activities to facilitate aggregation or federation such as the national pilot service ePrints UK.
In a similar manner, data repositories have been created on a national basis [22] [23], on a subject basis [24] and even about particular species [25]. More recently, Grid-enabled UK e-science projects such as AstroGrid [26] and GriPhyN [27] which are highly data-centric, are generating peta-bytes of data and require advanced tools for data management and data-mining. The move towards a distributed Virtual Observatory will also require new distributed search and query tools such as SkyQuery [28] and Web Services form a key component of the technical infrastructure underpinning this development.
From a scholarly perspective, the strategic importance of institutional repositories has been articulated by Clifford Lynch [29] and he notes their potential for addressing data dissemination and preservation in addition to their role in managing other scholarly outputs. Digital asset management systems such as DSpace [30] support the storage of datasets as well as other digital formats. New projects are underway to investigate the issues around the preservation of institutional research data in the JISC-funded Supporting Institutional Records Management Programme [31].
Whilst the case for institutional repositories has been well-presented in a SPARC Position Paper [32], there is evidence that the authors themselves, i.e. academic researchers, appear to be reluctant to deposit and share information in this way [33] [34]. The cultural barriers and issues of intellectual property rights and quality control that have been identified as concerns to academics are being investigated in the JISC FAIR Programme/CURL-funded TARDIS [35], RoMEO [36] and SHERPA [36] projects. A further key issue is the research impact factor element in the context of freely-available electronic publications and this has been addressed in a recent paper by Stevan Harnad and colleagues [38]. Will similar reservations be expressed by academics when asked to deposit their research data in institutional repositories? To further complicate the picture, in some disciplines such as biomedicine, there are difficult issues of sensitivity, privacy and consent which act as barriers to the availability of electronic data and information. In summary, it is vital that the socio-economic and cultural barriers are addressed in parallel with the technological challenges.
Assuring the provenance of digital resources
Provenance is a well-established concept within the archives community [39] and in the art world [40][41], where the lineage, pedigree or origins of an archival record or painting are critical to determining its authenticity and value. It is of equal importance in science where the provenance or origin of a particular set of data is essential to determining the likely accuracy, currency and validity of derived information and any assumptions, hypotheses or further work based on that information [42]. Significant research has been carried out on describing the provenance of scientific data in molecular genetics databases SWISSPROT and OMIM [43] and in collaborative multi-scale chemistry initiatives [44]. The topic has recently been explored in a workshop at the Global Grid Forum (GGF6) in relation to Grid data [45] and the relationship of provenance to the Semantic Web has been noted [46]. The Open Archives Initiative has also carried out some work to describe the provenance of harvested metadata records [47] and the concept is included as an element in the administrative metadata which is part of the METS [48] metadata standard.
eBank will be reviewing the body of work on provenance, describing the observed trends and directions, and will particularly focus on the relationship between the creation, curation and management of research data and its integration into published information resources which are contained in digital libraries.
Metadata descriptions and common ontologies
A recent joint UKOLN/National e-Science Centre (NeSC) Workshop [49] [50], Schemas and Ontologies: Building a Semantic Infrastructure for the Grid and Digital Libraries explored some generic challenges which creators of digital libraries and Grid data repositories need to address. More specifically, eBank will be considering a wealth of metadata issues relating to the perceived hierarchy of data and metadata from raw data up to “published” results. These include the need to identify common attributes of a dataset and relate them to domain-specific characteristics, managing legacy data, dealing with metadata created at source by laboratory equipment and the relationship to wider data curation activities. The Combechem project will act as a discrete case study and metadata from three sources (e-Lab book, crystallography data and physical chemistry data) will be used to inform the drafting of a schema for describing chemistry datasets.
Impact on the wider community and on research and learning processes
It is hoped that the outcomes of the project will have the potential for very significant long-term impact on the whole scholarly communications process. The availability of original data, together with the ability to track its use in subsequent research work, scholarly publications or learning materials, will have outcomes in a number of areas:
- It will be possible to track more accurately the protocols, mechanisms and workflows integral to the research process. Referees will be able to validate more effectively the accuracy and authenticity of derived works which will lead to a more transparent and auditable process. In addition the accepted standards associated with the publication of research outputs will be raised, which will enhance the integrity and rigour of the scholarly knowledge cycle and facilitate the explicit referencing and acknowledgment of original contributors
- Access to research outputs will be greatly improved and will benefit the wider community of scholars. It will be possible to increase the speed of dissemination of research activity for the benefit of the wider community. The ways in which data and information are used and reused for a range of purposes will be expanded leading to potentially innovative applications and outcomes
- Learners will be able to examine the original data underpinning published work and use this information to inform their course work .The quality and richness of materials created for learning and teaching will be enhanced, whether these are digital materials for an online course or in support of more traditional delivery methods
Finally, it is clear that some historic scientific controversies would have been easier to resolve within an environment of assured data provenance, and we can cite the example of Rosalind Franklin [51]. She was one of the leading molecular biologists of the mid-twentieth century, who worked with James Watson, Francis Crick and Maurice Wilkins in the early 1950s. To this day, the debate continues on the significance of her role in determining the structure of DNA, in the absence of persistent digital evidence!
Acknowledgements
The contributions of Andy Powell (UKOLN) and Jeremy Frey (Combechem Project, University of Southampton) are gratefully acknowledged.
References
- Lyon, L. (2002) Developing Information Architectures - to support Research, Learning and Teaching, UCISA Conference, March 2002.
http://www.ukoln.ac.uk/distributed-systems/jisc-ie/arch/presentations/dev-inf-arch/intro_files/frame.htm
Frey, J., De Roure D. and Carr L. (2002) Publishing at Source: Scientific Publication from a Web to a Data Grid, EuroWeb 2002 Conference, Oxford. Dec 2002.
http://www.ecs.soton.ac.uk/~lac/publicationAtSource - Tony Hey, Anne Trefethen, The Data Deluge: An e-Science Perspective. http://www.rcuk.ac.uk/escience/documents/DataDeluge.pdf
- GenBank http://www.ncbi.nih.gov/Genbank/GenbankOverview.html
- BBSRC Bioscience for Society: A Ten-Year Vision. http://www.bbsrc.ac.uk/publications/policy/bbsrc_vision.html
[URL updated 2007-12-12 Ariadne] - A Learning Management System is taken to be synonymous with a Virtual Learning Environment or VLE.
- Combechem Project http://www.combechem.org/
- EPSRC UK National Crystallography Service in the Chemical Crystallography Laboratory at the Department of Chemistry, University of Southampton
http://www.soton.ac.uk/~xservice/ - JISC Semantic Grid & Autonomic Computing Programme
http://www.jisc.ac.uk/index.cfm?name=programme_semantic_grid - PSIgate http://www.psigate.ac.uk/newsite/
- The JISC Information Environment Architecture http://www.ukoln.ac.uk/distributed-systems/jisc-ie/arch/
- ePrints UK Project http://www.rdn.ac.uk/projects/eprints-uk/
- Ruth Martin. ePrints UK: Developing a national e-prints archive. Ariadne , 2003. http://www.ariadne.ac.uk/issue35/martin/
- Open Archives Initiative http://www.openarchives.org/
- RDN http://www.rdn.ac.uk/
- RDN-Include http://www.rdn.ac.uk/rdn-i/
- Web Services for Remote Portlets (WSRP) http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=wsrp
- Stevan Harnad. Free at Last- The Future of Peer-reviewed Journals. D-Lib Magazine, 1999. http://www.dlib.org/dlib/december99/12harnad.html
- Cogprints http://cogprints.ecs.soton.ac.uk/
- arXiv http://arxiv.org/
- University of Bath: ePrints@Bath http://eprints.bath.ac.uk/
- University of Nottingham ePrints http://www-db.library.nottingham.ac.uk/eprints/
- UK Data Archive http://www.data-archive.ac.uk/
- UK Census Datasets http://census.ac.uk/cdu/datasets/
- NERC Environmental Data Centre http://www.nerc.ac.uk/data/
- FlyBase http://flybase.bio.indiana.edu/
- AstroGrid project http://www.astrogrid.org/
- GriPhyN Project http://www.griphyn.org/index.php
- SkyQuery http://www.skyquery.net/main.htm
- Clifford Lynch ARL Bimonthly Report 226, February 2003 http://www.arl.org/newsltr/226/ir.html
- DSpace http://dspace.org/index.html
- JISC Supporting Institutional Records Management Programme
http://www.jisc.ac.uk/index.cfm?name=programme_supporting_irm - SPARC Position Paper http://www.arl.org/sparc/IR/ir.html
- Stephen Pinfield, Mike Gardner and John MacColl, Ariadne, 2002. http://www.ariadne.ac.uk/issue31/eprint-archives/
- Stephen Pinfield D-Lib Magazine March 2003. http://www.dlib.org/dlib/march03/pinfield/03pinfield.html
- TARDIS Project http://tardis.eprints.org/
- RoMEO Project http://www.lboro.ac.uk/departments/ls/disresearch/romeo/
- SHERPA Project http://www.sherpa.ac.uk/
- Stevan Harnad et al Mandated online RAE CVs linked to university eprint archives: enhancing UK research impact and assessment. Ariadne , March/April 2003. http://www.ariadne.ac.uk/issue35/harnad/
- David Bearman & Richard Lytle. The Power of the Principle of Provenance. Archivaria, 21, p14-27, 1985.
- Getty Provenance Index http://piedi.getty.edu/
- Museum of Modern Art, New York. Provenance Project http://www.moma.org/provenance/
- Peter Buneman et al Why and Where:A Characterization of Data Provenance http://db.cis.upenn.edu/DL/whywhere.pdf
- Peter Buneman et al Archiving Scientific Data http://www.cis.upenn.edu/~wctan/papers/02/sigmod02.pdf
- Collaboratory for the Multi-scale Chemical Sciences CMCS http://cmcs.ca.sandia.gov/index.php
- Data derivation and provenance workshop GGF6 http://www-fp.mcs.anl.gov/~foster/provenance/
- Carole Goble Position Statement at GGF6 Workshop.
- Open Archives Initiative guidelines http://www.openarchives.org/OAI/2.0/guidelines-provenance.htm
- METS http://www.loc.gov/standards/mets/
- UKOLN/NeSC Schemas & Ontologies Workshop http://www.nesc.ac.uk/action/esi/contribution.cfm?Title=163
- John MacColl Metadata Wanted for the Evanescent Library, Ariadne issue 36 http://www.ariadne.ac.uk/issue36/maccoll-rpt/
- Rosalind Franklin Brief Biography http://www.sdsc.edu/ScienceWomen/franklin.html
Author Details
Dr Liz Lyon Email: e.lyon@ukoln.ac.uk |
Article Title: “eBank UK: Building the links between research data, scholarly communication and learning” Author: Liz Lyon
Publication Date: 30-July-2003 Publication: Ariadne Issue 36
Originating URL: http://www.ariadne.ac.uk/issue36/lyon/