Web Focus: WWW 2003 Trip Report
WWW 2003 was the 12th in the series of international World Wide Web conferences organised by the IW3C2 (the International World Wide Web Conference Committee). The international WWW conferences provide an opportunity for the Web research community to describe their research activities. Other tracks at the conference cover areas such as cultural resources, e-learning, accessibility, etc. In addition W3C (the World Wide Web Consortium) gives a series of presentations which describe many of the new Web standards being developed.
As I did not attend last year’s conference it was particularly useful to see how things had progressed over the past two years. A summary of some of the highlights of the conference is given below. Note that many of the papers and presentations from WWW 2003 are available on the conference Web site [1].
Conference Highlights
In my trip report of WWW10 held in Hong Kong in 2001 I wrote in issue 28 [2]:”The future of the Semantic Web was one of the main topics of discussion at the conference. Some felt that the Semantic Web was too much of an abstract research concept and that, in the light of experiences in the field of AI and Expert Systems, it would not be sensible to invest heavily in the development of Semantic Web services.”.
At WWW 2003 it was apparent that the Semantic Web was no longer an abstract concept: many of the papers and posters were concerned with the Semantic Web and we were seeing a number of demonstrators in a range of areas. Perhaps the ‘coolest’ Semantic Web application is FOAF (Friends of a Friend) [3]. This application is based on the six-degrees-of-separation theory that there are at most six links between you and any other person. FOAF is a Semantic Web application which enables you to provide links to your friends. If your friends also have FOAF files you can then follow links from their friends, and so on.
An example of a FOAF application is shown in Figure 1.
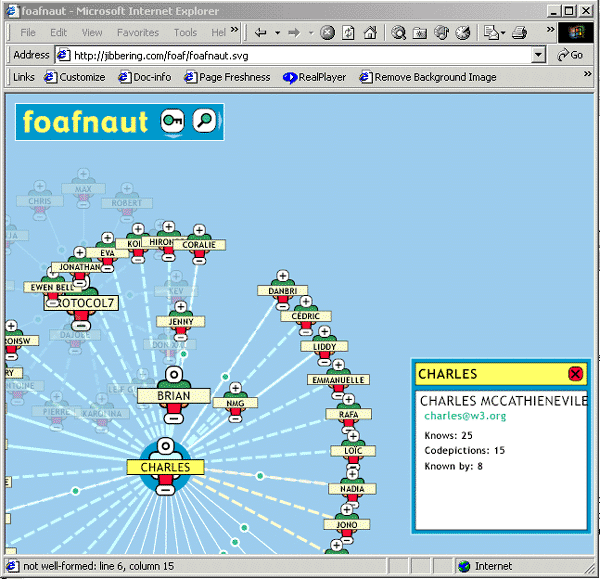
Figure 1: The FOAFNAUT Application
Figure 1 shows the FOAFNAUT application. I have given my email address as the entry point. My friends, defined in my FOAF file, are then displayed. One of the entries is for Charles McCathieNeville, one of the early FOAF developers. By clicking on his entry, I can then see a display of his friends, as illustrated.
This example illustrates a number of important concepts:
- Typed links: the link being followed has the meaning “is a friend of”. Contrast this with the conventional Web in which links can mean anything
- Integration of data from diverse sources: when I click on the link to Charles, the data is retrieved from Charles’ Web site. The data is not stored centrally within a single application as is the case for similar applications
- Extensibility: the data is not only held remotely, but can also be extended. For example, Charles’s FOAF file also also contains a link to a photograph and information on the languages he speaks and his interests. FOAF applications can process such information: FOAFNAUT, for example, will display photographs; other applications, such as a Semantic Web spider, could be programmes to find people who speak the same languages as I do or have similar interests
FOAF has become very popular amongst Web geeks. It may well turn out to be a useful mechanism for promoting the Semantic Web from the grass roots, as opposed to the top-down approach which typically requires significant commitment from organisations. There is also a need to consider the potential for the Semantic Web from an institutional perspective. At the conference I was informed of a Semantic Web application which provides an application likely to be of interest to the institutional Web management community. The application, which has been developed by a research group at the University of Southampton, takes data from a number of public Web sites including the RAE findings (from the HERO Web site) and from Computer Science departmental Web sites within the UK Higher Education community. These unstructured HTML pages are converted into RDF and are available from the Hyphen Web site [4]. An application has been developed which enables the data, which originally came from multiple sources developed independently of each other, to be integrated. An example of the AKTiveSpace application [5] (which requires the Mozilla browser) is shown in Figure 2.
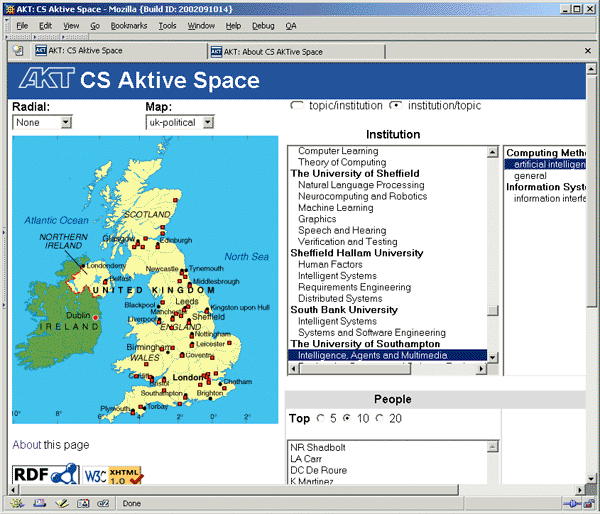
Figure 2: The AKTiveSpace Application
The AKTiveSpace interface allows the user to view a list of leading researchers ordered by total grant income by expressing constraints which apply to them; for example, by the research groups or by the subject disciplines in which they work. It should be noted that an AVI file is available which shows a session of the tool [6].
This demonstration shows how it should be possible to integrate data seamlessly from multiple sources and interact with the data. Of course, in this example the data has been downloaded to a central file store and transformed into RDF. In order for the Semantic Web to take off the preferred model would be for institutions to store their own data.
W3C Track
Although much of the excitement at WWW 2003 focussed on the area of the Semantic Web, the W3C track was also very useful in providing an opportunity to hear about emerging new W3C standards.
Steve Bratt, W3C’s Chief Operating Officer, opened the W3C track by giving a W3C Overview [7]. This was followed by Ivan Harman’s talk which gave a High-Level Overview of W3C Technologies [8].
Following these two overview talks Daniel Weitzner outlined W3C’s new patent policy [9]. The policy, announced on 20 May 2003, (the day before the conference opened), seeks to ensure that W3C recommendations are implementable on a royalty-free basis. This is very good news, and W3C should be applauded for addressing this tricky legal issue and successfully implementing a policy.
The second W3C track session covered The Future Web Browser. Stephen Pemberton talked about XHTML 2.0 and XForms [10]. Although XHTML 1.0 should benefit from being an XML application, in reality most XHTML 1.0 resources are, in fact, not compliant with the XML specification. Since the XML specification requires XML resources to be compliant (unlike HTML, in which the specification expects browsers to attempt to render non-compliant resources) it is difficult to exploit the potential of XML. XHTML 1.0 is severely compromised by its design aim of providing backwards compatibility with existing Web browsers.
XHTML 2.0 is designed based on following fundamental XML principles. Backwards compatibility is not a requirement for XHTML 2.0! This provides an opportunity to reengineer the HTML language - for example it is proposed that the <h1>, <h2>, etc. elements will be replaced by <h> in conjunction with a new <section> element.
The deployment model for XHTML 2.0 is based on use of a new MIME type. Web browsers which can process XHTML 2.0 resources will identify such resources by the new MIME types and will be able to process them using an XML parser; current XHTML 1.0 and HTML resources will be processed using existing HTML parsers. The expectation is that the benefits of working in a clean XML world (faster processing based on a document’s DOM; clean integration with other markup languages such as MathML, SVG, etc.; easier repurposing of data; etc) will be so overwhelming that Web developers will quickly move to an XHTML 2.0 environment.
Although it would be easy to be sceptical as to whether the Web community is ready for such a fundamental change to its native format, it should be pointed out that there will be automated tools available to assist in migration. In addition we are beginning to see examples of how XHTML 2.0 can be deployed in today’s environment. The following image illustrates the rendering of an XHTML resource in an existing browser.
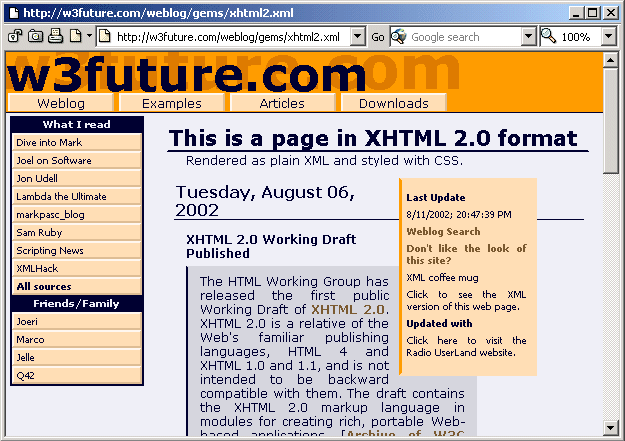
Figure 3: Viewing An XHTML 2.0 Document
You may wish to see an example of XHTML 2.0 code fragment.
In the second talk in the track Bert Bos described CSS 3 [11]. This talk was not as radical as Stephen Pemberton’s; it covered a number of developments to the CSS stylesheet language, including enhanced ways of rendering hyperlinks, layout for forms (including XForms) and many other improvements such as columns, print, list numbering, wrapping around floats, etc.
The most impressive demonstration was given in the third talk in the track, in which Dean Jackson described Applications of SVG [12]. Most of the demonstrations Dean gave are available online, but it should be noted that you will need to have an SVG plugin in order to view them.
Many of the demonstrations are very visual and interactive and so will not be described here. However one which should be mentioned is foafCORP [13]. This has many similarities to FOAF (in fact Dean’s ideas were the inspiration for the FOAFnaut application), but it illustrates relationships amongst the boards of directors of large companies in America - it describes itself as “a semantic web visualization of the interconnectedness of corporate America”.
Use of a foafCORP viewer [14] is shown below. The application opens with a list of companies. After selecting one, you can then expand an icon representing the company (a dollar sign) to obtain details of the directors of the company, (represented by fat cats!) You can then click on an icon to display other companies where an individual is also on their board of directors. As can be seen from Figure 4, there is a very short chain between Coca-Cola and Pepsi-Cola.
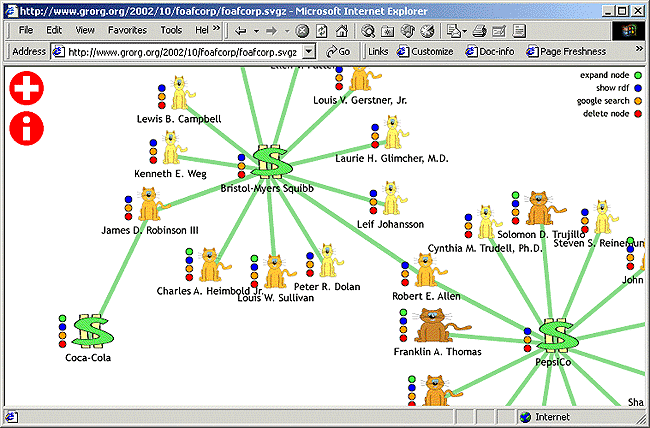
Figure 4: foafCORP
This example is particularly noteworthy as, rather than demonstrating interesting visual effects as many of the other SVG demonstrations did, this illustrates the way in which SVG can visualise data elements and provide interaction with the data.
In the final talk in the session on The Future Web Browser, Chris Lilley sought to Pull It All Together [15]. Chris reviewed the new standards which had been shown, (XHTML 2.0, XForms, CSS 3.0, and SVG). He pointed out there were many other formats and standards which end users would like to access, including SMIL, MathML, RDF metadata, etc. Chris’ view of the future is not based on a monolithic Web browser which provides support for all these new standards. This approach is flawed, not only due to the difficulties in developing browsers able to support a large number of standards, (including standards yet to be developed!), but also because there are a number of fundamental Web architectural challenges which have not yet been resolved: a number of new formats have defined their own mechanisms for hyperlinking; there are problems in identifying ID semantics in XML languages which do not have a DTD, and so on.
In the light of these challenges, Chris feels that there is a need for a browser component architecture. This architecture will provide a mechanism for aggregating components, ensure that the browser components are separated from the content and will provide better integration.
The W3C is now only involved in developing new standards for the Web. It also has a QA activity which seeks to support the development process for W3C specifications. The QA work also addresses the needs of Web developers and maintainers who are responsible for managing Web sites. Daniel Dardailler gave an outline of the Quality Assurance Goals [16]. Dominique Hazaël-Massieux then described Outreach Resources and Tools For a Better Web [17] and Olivier Thereaux spoke on Community-driven tools development for a better Web [18].
Other W3C sessions covered Five Years and Growing: The XML Family, W3C Standards for Web Services, Semantic Web Update, Preparing for New Devices and Horizontal Essentials. The slides for all of the talks in these sessions are available from the Talk area of the W3C Web site [19].
Panel Session
As well as getting an update on W3C developments and hearing about research activities this year I moderated a panel session on Web Accessibility: Will WCAG 2.0 Better Meet Today’s Challenges? [20]. The panelists consisted of myself, Jenny Craven (CERLIM, Manchester Metropolitan University) and Judy Brewer and Wendy Chisholm (W3C WAI). The panel session was meant to provide an opportunity to engage in discussion on the challenges of implementing Web accessibility and compliance with WAI’s Web content accessibility guidelines. Unfortunately the session did not really provide an opportunity for debate and we really saw a standard update on the forthcoming revision of the Web content accessibility guidelines.
Conclusions
Two years ago I felt that the Web was finally losing its momentum and was reaching a period of consolidation, with the emphasis on refinements to the underlying Web architecture (focussing on technologies such as XML and Web Services). I felt that the W3C would spend its time dealing with political, funding and legal issues (such as patents). W3C, and the broader Web community have been addressing such issues. But I think it’s also true to say that with technologies such as Semantic Web applications, SVG and XHTML 2.0 just around the corner that the Web is regaining the excitement of the early years. If these technologies do take off in real world applications it will be certainly an interesting time for the Web community.
The WWW 2004 conference [21] will take place in New York, USA from 17-22 May.
References
- The Twelfth International World Wide Web Conference,
http://www.www2003.org/ - Hot News From WWW10, Brian Kelly, Ariadne, issue 28,
http://www.ariadne.ac.uk/issue28/web-focus/ - FOAF: the ‘friend of a friend’ vocabulary, RDFweb
http://xmlns.com/foaf/0.1/ - Hyphen.info,
http://www.hyphen.info/ - AKT: CS Aktive Space, AKT Triplestore
http://triplestore.aktors.org/demo/AKTiveSpace/ - View a video of CS AKTiveSpace in action, AKT Triplestore
http://triplestore.aktors.org/demo/AKTiveSpace.avi - Introduction and W3C’s Process, Steve Bratt, W3C
http://www.w3.org/2003/Talks/0521-sb-wwwintro/ - High-Level Overview of W3C Technologies , Ivan Herman, W3C
http://www.w3c.org/2003/Talks/0521-BudapestW3CTrack-IH/ - W3C Patent Policy , Daniel J. Weitzner, W3C
http://www.w3.org/2003/Talks/0521-www-patent/ - XHTML 2.0 and XForms , Stephen Pemberton, W3C
http://www.w3.org/2003/Talks/www2003-steven-xhtml-xforms/ - CSS 3.0, Bert Bos, W3C
http://www.w3.org/Talks/2003/0521-CSS-WWW2003/all.htm - Applications of SVG, Dean Jackson, W3C
http://www.w3.org/2003/Talks/www2003-svg/ - FOAFCorp: Corporate Friends of Friends, RDFWeb
http://rdfweb.org/foaf/corp/intro.html - foafCORP viewer, Dean Jackson, W3C
http://www.grorg.org/2002/10/foafcorp/ - Pulling It All Together, Chris Lilley, W3C
http://www.w3.org/2003/Talks/www2003-pullingItAllTogether/0.svg - Quality Assurance Goals , Daniel Dardailler, W3C
http://www.w3.org/2003/Talks/www2003-qa/ - Outreach Resources and Tools For a Better Web , Dominique Hazaël-Massieux, W3C
http://www.w3.org/2003/Talks/www2003-specGL/ - Community-driven tools development for a better Web, Olivier Thereaux, W3C
http://www.w3.org/2003/Talks/www2003-QATools/ - W3C Track, W3C
http://www.w3.org/2003/03/w3c-track03.html - Web Accessibility: Will WCAG 2.0 Better Meet Today’s Challenges?, Brian Kelly, UKOLN
http://www.ukoln.ac.uk/web-focus/events/conferences/www2003/ - WWW2004 - Thirteenth International World Wide Web Conference,
http://cat.nyu.edu/www2004/
Author Details
Email: b.kelly@ukoln.ac.uk Brian Kelly is UK Web Focus. He works for UKOLN, which is based at the University of Bath |
 Brian Kelly
Brian Kelly{kind=link}
Article Title: “Web Focus: WWW 2003 Trip Report”
Author: Brian Kelly
Publication Date: 30-July-2003
Publication: Ariadne Issue 36
Originating URL: http://www.ariadne.ac.uk/issue36/web-focus/