The Resource Discovery Project
Resource Discovery at DSTC
The Resource Discovery Project is one of the major research units of the Distributed Systems Technology Centre (DSTC). The DSTC is one of over 60 co-operative research centres in Australia and is a Federally and commercially funded non-profit company. The DSTC has over 25 participating organisations which provide resources to the research program, including, direct funding, seconded staff, hardware and software, and importantly, research problems. The Resource Discovery Project was established in mid 1994 after the emerging problem of information discovery on large networks was identified as a crucial research area for Australian data networks.
The goal of the Resource Discovery Project is to investigate issues related to locating, retrieving, and promulgating information in large networked environments. The Internet and WWW provide a challenging environment for deployment of these services. The needs of information publishers - to maximise audience reach - and the user - to minimise information overload - require advanced technical solutions and investigative research.
The Resource Discovery Project framework assumes the three layer architecture shown in Figure 1. The framework contains the following entities:
- Content Seekers - what technology do users need to find the information they are seeking? What technologies do users need for retrieving and managing resources? Users require software clients with intuitive user interfaces to facilitate and manage simple and complex information retrieval tasks.
- Discovery Services - what mechanisms do you need to store, propagate, and manage the resource descriptions used by the users to select and retrieve resources? Discovery services act as the intermediary between the users and the information providers - matching the needs of the two - to provide a unified view of information repositories.
- Content Providers - how do you describe your resources? Various techniques can be used to provide descriptions of resources (metadata) and to support the management of the organisation’s information publishing strategies. These include tools which automate metadata extraction and support access constraints.
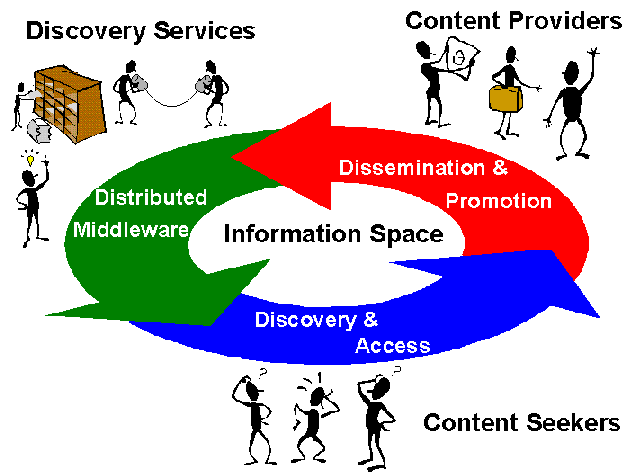
Figure 1: Resource Discovery Project Framework
Key Ideas and Goals of the Research
The Resource Discovery Project is aiming to provide timely solutions to some of today’s problems as well as a fundamental and applied research vision. The following outlines the projects goals, key ideas and research rationale:
- Goal: Allow organisations to effectively disseminate and promote networked information both internally and externally.
- Key Idea: Accurate resource descriptions and robust naming systems are essential for finding resources.
- Research plan: Investigate techniques for describing and identifying resources. Investigate technologies for producing and disseminating resource descriptions and identifiers.
- Goal: Improve information discovery and access across heterogeneous information sources.
- Key Idea: Information and services will be made available in various formats and protocols and no single standard will ever evolve.
- Research plan: Use middleware discovery services to translate between the various formats and standards.
- Goal: Provide scaleable and manageable solutions for networked information promotion and discovery.
- Key Idea: Large information spaces are often distributed, heterogeneous, dynamic, and expanding.
- Research plan: Create scaleable discovery services using distributed middleware techniques.
- Goal: Improve user access to resources through better extraction of information needs and more effective information filtering.
- Key Idea: Users have difficulty expressing their information needs and coping with the large amounts of information which may meet their needs.
- Research plan: Investigate techniques for extracting and applying user information needs and for filtering information.
Technologies and Prototypes
The Resource Discovery Project has investigated a number of the above issues and has produced prototypes to demonstrate various solutions. These are described below.
Naming
Naming is area receiving increasing attention as it is fundamental to the capabilities of many systems in distributed networking. The rapid growth of the World-Wide Web has seen the Uniform Resource Locator (URL) scheme being used as the de facto naming system for the Internet. The next generation of naming will however provide more flexibility - with the development of Uniform Resource Names (URN).
The Resource Discovery Project has developed a URN resolver [1] based on the standard HTTP protocol and which supports various resolution media types (text, html, or sgml). The major problem faced is not in the technologies, but in the deployment, utility and ease of use of tools for creating and managing URN systems. URLs are easy to create, but pose a legacy problem. URNs are more complex, but will be more persistent and stable.
The importance of effective and flexible schemes for URNs will be paramount for their early deployment.
Metadata
Metadata is a significant area of research in the Resource Discovery Project [2] and there are a number of aspects to this research.
The first research issue which must be addressed is what set of information is to be captured by the metadata. This depends on the type of the resource and on the purpose of the metadata. A metadata scheme must be sufficiently flexible to capture useful information about a wide variety of resources for a range of purposes. Ideally, a single metadata scheme should be used as this minimises the cost of using metadata. Unfortunately, it is unlikely that there will ever be agreement on a single metadata scheme and so a major aspect of metadata research is the relationship between different metadata schemes and the trade-off between the size and utility of the metadata element set.
The second research issue is related to the production of metadata. Metadata is essentially a summary of the data produced by various levels of abstraction. Using humans to generate these summaries is expensive and metadata systems attempt to reduce this cost by automating as much of the process as possible.
The final research issue of metadata concerns how the metadata is accessed and used. It must be retrieved in a form which can be processed with its semantics preserved. An important use of metadata is as a mechanism for resource location in distributed networks like the Internet. Metadata can provide information for the user to identify which resources they might be interested in. Once a resource has been identified, metadata provides the information to allow the resource to be accessed.
The Resource Discovery Project is working on the following metadata related projects:
- Indexing Dublin Core (using Harvest) and other metadata embedded in HTML files and providing a search interface to this database.
- Using Dublin Core for describing resources for URN resolution services.
- Using Dublin Core to map search results from Web servers (HTTP) and library catalogues (Z39.50) into a meta-search engine.
- Using Dublin Core and GILS metadata in X.500 Directories to support the Warwick Framework and the Trading services defined by the Open Distributed Processing group.
- Extending PICS to support Dublin Core and other text-based metadata.
- Extending the Persistent URL (PURL) system to support Dublin Core metadata.
The Resource Discovery Project is also involved in the fundamental area of ontologies. An ontology is a set of standard concepts, terms and definitions which are agreed upon within a particular community. People often use different terms to refer to the same concept and they use the same term to refer to different concepts. It is very difficult to find resources if they have been described using inconsistent terms. We have been involved in implementing a system which suggests appropriate terms to users when classifying documents and allows users to refine this classification and evolve the ontology.
Z39.50
The Resource Discovery Project recognised that large information providers needed a standard and flexible information retrieval protocol, and that Z39.50 is the leading standard. The US Government Information Locator Service (GILS) has also mandated the use of Z39.50 as its primary protocol for agencies.
The main focus of the research work has been on building flexible mechanisms for building Z39.50 access to various databases formats (for example, the Harvest database). We also built a Z39.50 to X.500 Gateway system [3] to demonstrate the utility of Z39.50 and its ability to access Directory Services within the GILS environment.
The Web and Z39.50 have become very popular as Libraries and other information providers are adopting the Z39.50 information retrieval standard for accessing their on-line catalogues. We have compared and reviewed many of the leading Clients and Web Gateways [4]
The future of Z39.50 is unclear. On the one hand, developers are in need of a standard and flexible information retrieval protocol, on the other, they want an easy and lightweight solution to the problem. The Z39.50 community is attempting to solve this by defining a light version of Z39.50. The Resource Discovery Project is also investigating the requirements of the Internet community for a lightweight information retrieval protocol as an alternative to Z39.50 [6].
Browsing
The Web is large, too large in fact for normal users to cope with the amount of information shown using normal information presentation methods. The Resource Discovery Project has been experimenting with an information presentation tool called the HyperIndex Browser (HIB) which helps users define queries and navigate large information spaces. Users may not know the exact query terms to use when searching for information. The HIB lets users enter general, encompassing terms as queries. It then extrapolates the “information space” around that search term and presents the user with a number of related topics to select from: refinements which narrow the focus of the search, and enlargements which broaden the focus. For example, in response to the initial search term internet security, the HIB might present you with the following suggestions shown in Figure 2 below.

Figure 2: HyperIndex Browser
Currently the HyperIndex Browser assists the user in coping with information overload and query construction. The next stages of the research include using the path navigated through the HIB to build a profile of that user’s interests. This profile can then be used to guide future resource discovery activities.
Heterogeneous Meta-Searching
Searching multiple information servers is obviously a significant area of work for Resource Discovery systems. The Resource Discovery Project has developed such a meta-searcher called HotOIL [5]. HotOIL assumes that resources are stored in many different types of information repositories (such as an enterprise’s databases and a public Internet catalogue) and that these repositories are distributed widely over computer networks. To find information without HotOIL you would need to interact with each of these information repositories individually. HotOIL performs these interactions for you. Given your query:
- HotOIL consults a directory of information repositories and decides which are most likely to contain information relevant to your query.
- For each repository chosen in step 1, HotOIL:
- translates your request into a query for this repository
- sends the query to the repository
- retrieves the results
- moulds the results into a common internal format
- HotOIL merges the results returned from each repository and then displays a summary
HotOIL can currently access both HTTP services and Z39.50 servers. The HyperIndex Browser is used as the front end to HotOIL and effectively gives the feeling of seamless access to a single database. Internally, HotOIL uses URNs and metadata to describe the search engines that it accesses. It also uses the Dublin Core metadata set to describe the resources returned from each search engine.
The experience with HotOIL highlights the growing perception in the Internet community of the need for a standard interface to queriable networked information sources [6].
Proxy Search Engine
The fact that communities of common interest naturally occur within organisations can be used to enhance resource discovery. The Resource Discovery Project has developed the What’s Hot system [7] which is based on the observation that people in an organisation share common interests. If someone in an organisation requests information about a particular subject then it is likely that other people in the organisation have previously requested information about that subject, or will in the future.
The What’sHot proxy search engine intercepts a user’s request for information on a subject and directly responds with URLs which are both about that subject and are also popular within the organisation. If the request cannot be matched by the local proxy search engine then the request is passed to proxy search engines at other sites who respond with URLs if there is a match. The request is eventually passed to conventional search engines if no proxy search engine in the system can provide a match.
The innovation in What’s Hot is in the way in which:
- the proxy search engines recommend popular resources to each other, and
- the measurement of the popularity of an individual resource.
Periodic Discovery
The information available on the Internet is highly dynamic. New resources are continually being published, and existing resources change often. An unsuccessful search conducted today might yield useful results tomorrow. To address this problem, The Resource Discovery Project has developed the Orion prototype [8] which is a tool for locating new resources as they become available. Orion can be thought of as an agent which can periodically performs searches. The user is informed of new resources which may interest them. See Figure 3 below for an example of the Orion search interface.
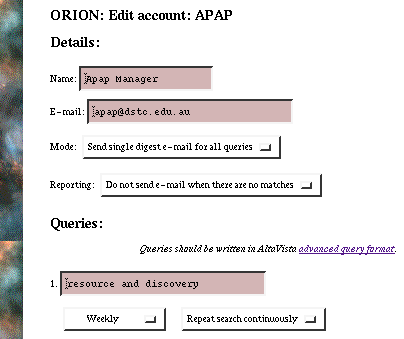
Figure 3: Orion
The technologies underlying Orion are the more interesting aspects of the prototype. Like HotOIL, Orion uses URNs and metadata to internally describe the external Web sites that it accesses.
Future Direction: Government Information Demonstrator
The prototypes and technologies developed as part of the Resource Discovery Project have now reached a level of maturity where they can be deployed in a real environment: Government information discovery and information promulgation. The Government provides a rich source of both information and scalability problems that will further challenge the Project.
The permanence of the government requires an architectural framework which is both scaleable and durable [9]. Figure 4 outlines the broad architecture that the Resource Discovery Project will be aiming to populate.
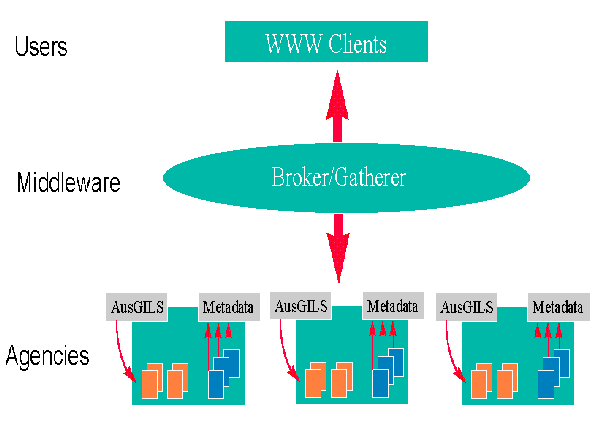
Figure 4: Whole-of-Government Architecture
The three layers in the architecture match those of Figure 1. The Agency layer deals with metadata for both individual-level and collection-level (AusGILS) resources. The Middleware layer looks at both the distribution of indexes (gathering) and the intelligent routing of queries (brokering). The User layer supports advanced client functions such as the HyperIndex browsing metaphor.
The technical strategies faced in developing a Whole-of-Government information access architecture are immense, including scalability, security and authentication, distributed indexing techniques, and future migration strategies. We believe that the Resource Discovery Project will be able to demonstrate solutions to some of these technical problems and are excited about the prospect of real deployment of our technologies.
![]()
Acknowledgements
Many thanks to the Resource Discovery Project team for their research work that is described in this report: Nigel Ward, Andrew Wood, Andrew Waugh, Ying Ni, Arkadi Kosmynin, Maria Lee, Mark French, Peter Bruza, Jane Hunter, Eric Proper, and Hoylen Sue.
The work reported in this paper has been funded in part by the Cooperative Research Centres Program, through the Department of the Prime Minister and Cabinet of Australia.
References
- Iannella, R & Sue, H & Leong D. BURNS: Basic URN Service resolution for the internet. Asia Pacific World Wide Web Conference, August 23-28 1996 (Beijing & Hong Kong)
http://www.dstc.edu.au/RDU/reports/APweb96/ - Iannella R & Waugh, A. Metadata: Enabling the Internet, CAUSE97 Conference, Melbourne, April 1997
http://www.dstc.edu.au/RDU/reports/CAUSE97/ - The Z39.50 to X.500 Gateway Prototype
http://www.dstc.edu.au/RDU/ZXG/ - Z39.50 Client and Web Gateway Surveys
http://www.dstc.edu.au/RDU/reports/zreviews/ - HotOIL Advanced Prototype Access Program
http://www.dstc.edu.au/BDU/APAP/HotOIL/HotOIL.html - Ward, N & Wood, A & Finnigan S, & Iannella I. Discussion Paper: Networked Information Retrieval Standards, 1996
http://www.dstc.edu.au/RDU/reports/webir.html - What’sHot Advanced Prototype Access Program
http://www.dstc.edu.au/BDU/APAP/WhatsHot/WhatsHot.html - ORION - Advanced Prototype Access Program
http://www.dstc.edu.au/BDU/APAP/Orion/Orion.html - Ianella, R. Networked Government Information Access - An Australian Perspective CNI Fall Task Meeting, San Francisco, December 1996
http://www.dstc.edu.au/RDU/reports/CNI96/
Author Details
Renato Iannella(Resource Discovery Project leader at the DSTC)
Home Page: http://www.dstc.edu.au/RDU/staff/ri/
Email: renato@dstc.edu.au
Phone: +61 7 3365 4310
Fax: +61 7 3365 4310
DSTC Home Page: http://www.dstc.edu.au/
Resource Discovery Project Home Page: http://www.dstc.edu.au/RDU/
DSTC Address: Gehrmann Labs, The University of Queensland, 4072, AUSTRALIA